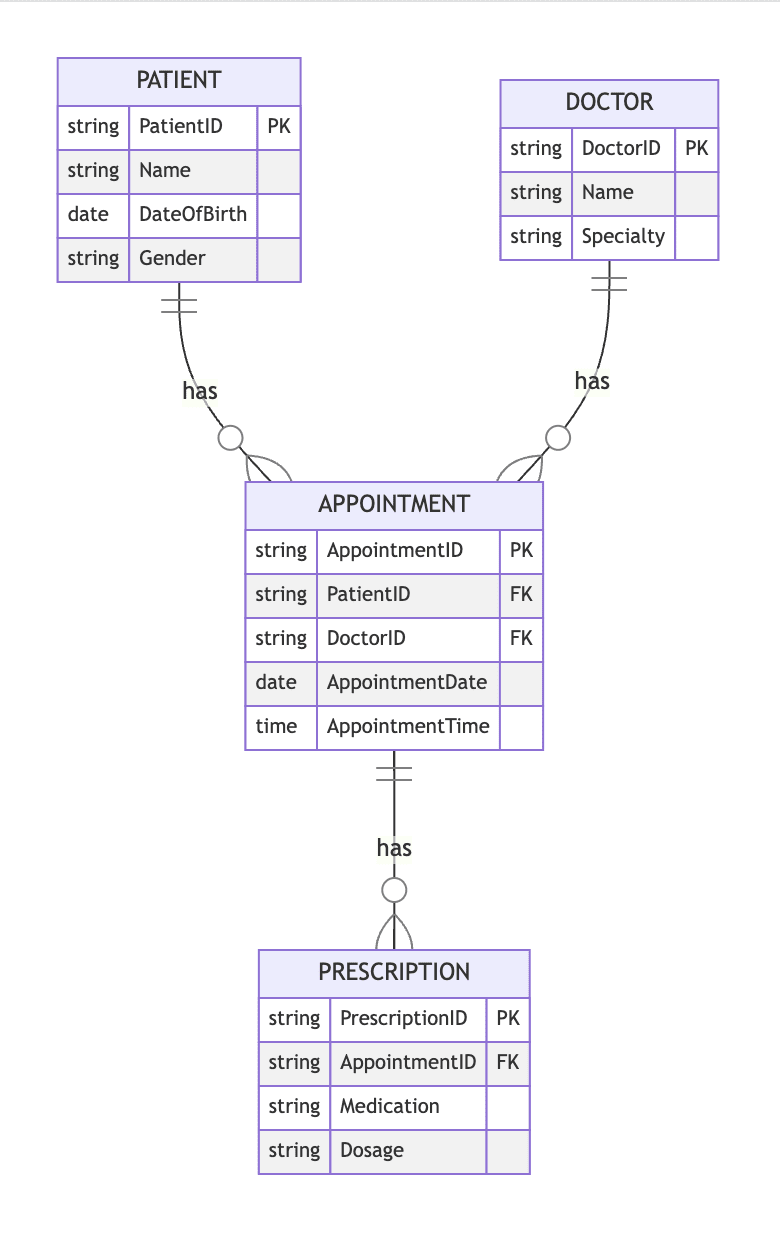
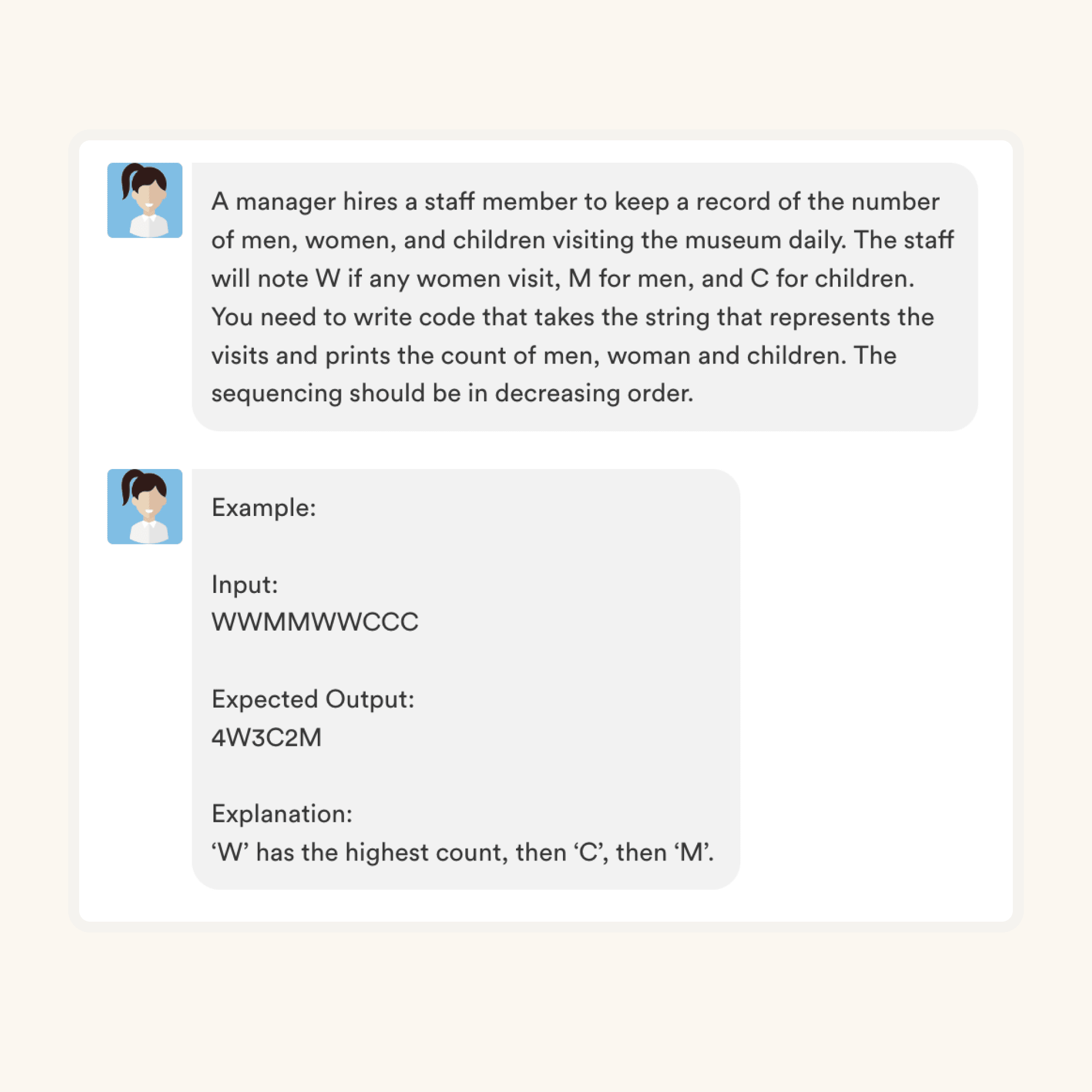
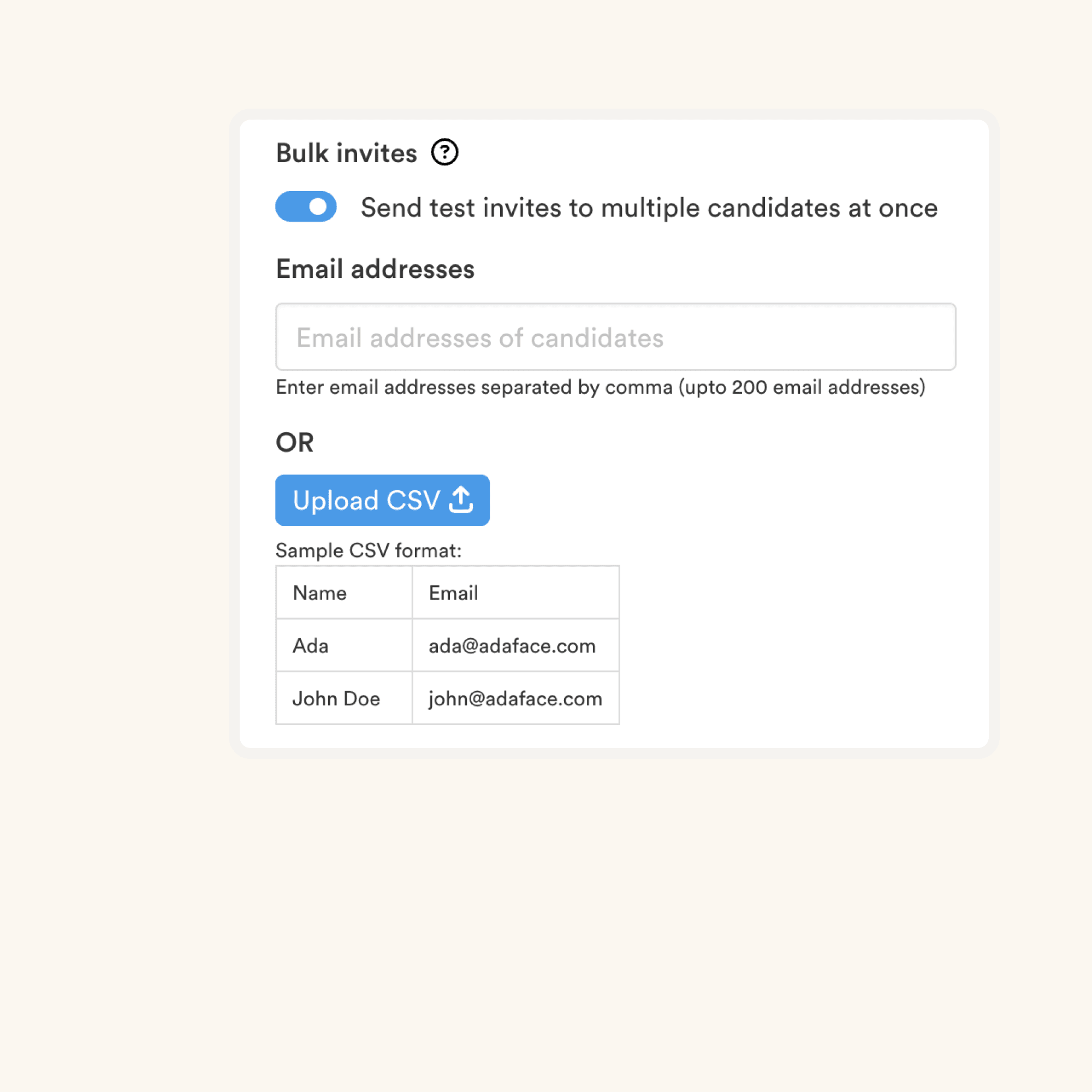
Test Duration
~ 40 minsDifficulty Level
Moderate
Questions
- 7 Data Mining MCQs
- 5 Data Modeling MCQs
- 5 ETL MCQs
Availability
Available as custom testThe Data Mining Test evaluates candidates on their knowledge of data mining techniques, data preprocessing, association rule mining, classification, clustering, and data visualization using scenario-based MCQs. In addition to these key skills, the test also assesses a candidate's understanding of data warehousing, data cleaning, and big data technologies.
Covered skills:
Test Duration
~ 40 minsDifficulty Level
Moderate
Questions
Availability
Available as custom testThe Data Mining Test helps recruiters and hiring managers identify qualified candidates from a pool of resumes, and helps in taking objective hiring decisions. It reduces the administrative overhead of interviewing too many candidates and saves time by filtering out unqualified candidates at the first step of the hiring process.
The test screens for the following skills that hiring managers look for in candidates:
Use Adaface tests trusted by recruitment teams globally. Adaface skill assessments measure on-the-job skills of candidates, providing employers with an accurate tool for screening potential hires.
We have a very high focus on the quality of questions that test for on-the-job skills. Every question is non-googleable and we have a very high bar for the level of subject matter experts we onboard to create these questions. We have crawlers to check if any of the questions are leaked online. If/ when a question gets leaked, we get an alert. We change the question for you & let you know.
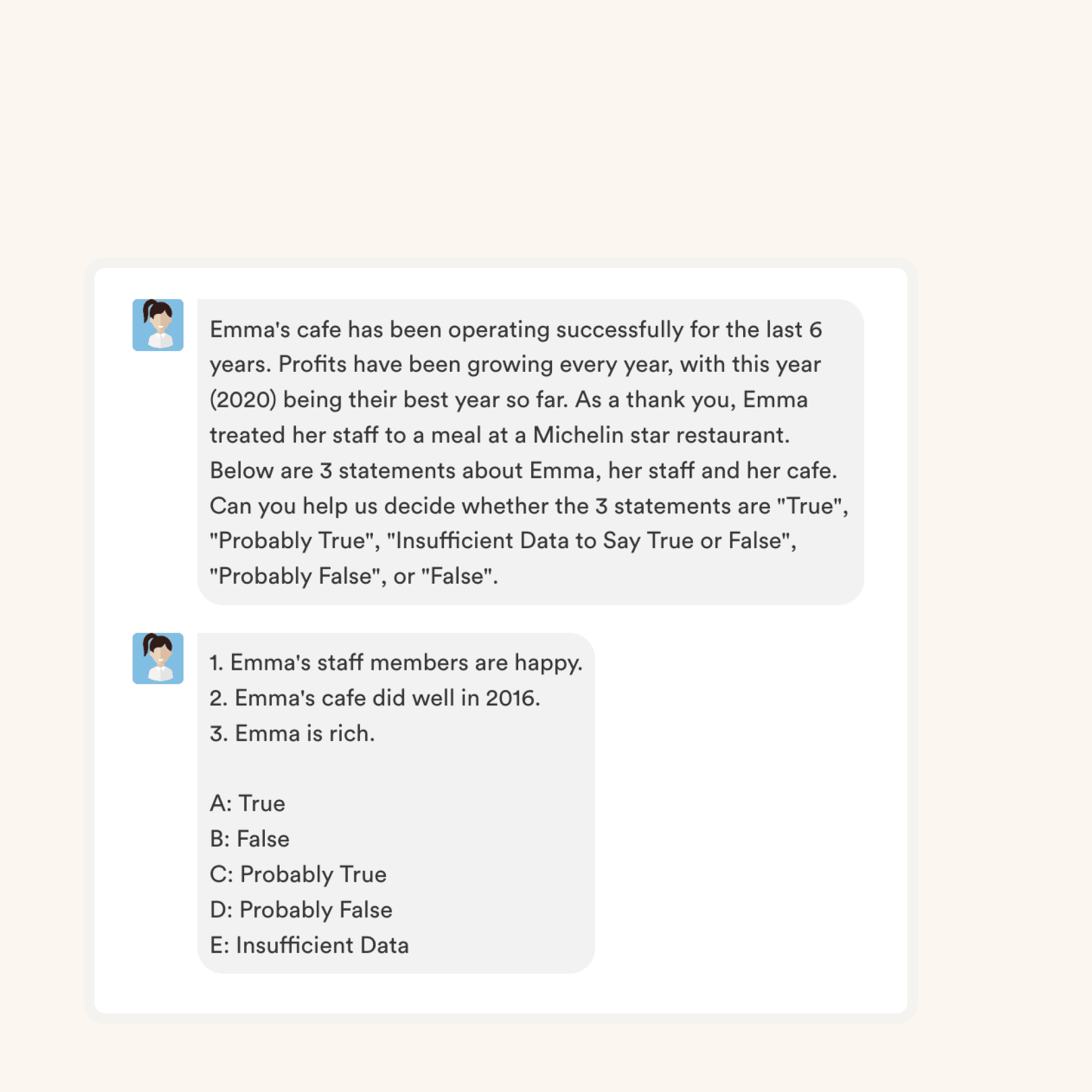
How we design questionsThese are just a small sample from our library of 15,000+ questions. The actual questions on this Data Mining Test will be non-googleable.
| 🧐 Question | |||||
|---|---|---|---|---|---|
|
Easy
Healthcare System
|
Solve
|
||||
|
|
|||||
|
Hard
ER Diagram and minimum tables
|
Solve
|
||||
|
|
|||||
|
Medium
Normalization Process
|
Solve
|
||||
|
|
|||||
|
Medium
University Courses
|
Solve
|
||||
|
|
|||||
|
Medium
Data Merging
|
Solve
|
||||
|
|
|||||
|
Medium
Data Updates
|
Solve
|
||||
|
|
|||||
|
Medium
SQL in ETL Process
|
Solve
|
||||
|
|
|||||
|
Medium
Trade Index
|
Solve
|
||||
|
|
|||||
| 🧐 Question | 🔧 Skill | ||
|---|---|---|---|
|
Easy
Healthcare System
|
2 mins Data Modeling
|
Solve
|
|
|
Hard
ER Diagram and minimum tables
|
2 mins Data Modeling
|
Solve
|
|
|
Medium
Normalization Process
|
3 mins Data Modeling
|
Solve
|
|
|
Medium
University Courses
|
2 mins Data Modeling
|
Solve
|
|
|
Medium
Data Merging
|
2 mins ETL
|
Solve
|
|
|
Medium
Data Updates
|
2 mins ETL
|
Solve
|
|
|
Medium
SQL in ETL Process
|
3 mins ETL
|
Solve
|
|
|
Medium
Trade Index
|
3 mins ETL
|
Solve
|
| 🧐 Question | 🔧 Skill | 💪 Difficulty | ⌛ Time | ||
|---|---|---|---|---|---|
|
Healthcare System
|
Data Modeling
|
Easy | 2 mins |
Solve
|
|
|
ER Diagram and minimum tables
|
Data Modeling
|
Hard | 2 mins |
Solve
|
|
|
Normalization Process
|
Data Modeling
|
Medium | 3 mins |
Solve
|
|
|
University Courses
|
Data Modeling
|
Medium | 2 mins |
Solve
|
|
|
Data Merging
|
ETL
|
Medium | 2 mins |
Solve
|
|
|
Data Updates
|
ETL
|
Medium | 2 mins |
Solve
|
|
|
SQL in ETL Process
|
ETL
|
Medium | 3 mins |
Solve
|
|
|
Trade Index
|
ETL
|
Medium | 3 mins |
Solve
|
With Adaface, we were able to optimise our initial screening process by upwards of 75%, freeing up precious time for both hiring managers and our talent acquisition team alike!
Brandon Lee, Head of People, Love, Bonito
It's very easy to share assessments with candidates and for candidates to use. We get good feedback from candidates about completing the tests. Adaface are very responsive and friendly to deal with.
Kirsty Wood, Human Resources, WillyWeather
We were able to close 106 positions in a record time of 45 days! Adaface enables us to conduct aptitude and psychometric assessments seamlessly. My hiring managers have never been happier with the quality of candidates shortlisted.
Amit Kataria, CHRO, Hanu
We evaluated several of their competitors and found Adaface to be the most compelling. Great library of questions that are designed to test for fit rather than memorization of algorithms.
Swayam Narain, CTO, Affable
The Adaface test library features 500+ tests to enable you to test candidates on all popular skills- everything from programming languages, software frameworks, devops, logical reasoning, abstract reasoning, critical thinking, fluid intelligence, content marketing, talent acquisition, customer service, accounting, product management, sales and more.
The Data Mining Test assesses candidates' proficiency in various data mining techniques including statistical analysis, decision trees, and clustering. It is useful for recruiters hiring data analysts and data scientists to ensure they have the necessary skills.
The test covers skills such as Data Processing, Data Warehouse and OLAP Technology, Data Preprocessing, Mining Frequent Patterns, Data Cleaning, Data Reduction, Data Mining Process, and Data Integration and Transformation.
Administer this test early in your recruitment process as a pre-screening tool. You can add a link to the assessment in your job post or invite candidates directly by email. This approach helps identify skilled candidates faster and more accurately.
Yes, recruiters can request a custom test that includes both Data Mining and Data Modeling questions. Check out our Data Modeling Skills Test for more details.
Some important tests in the Data Analysis category include:
Yes, absolutely. Custom assessments are set up based on your job description, and will include questions on all must-have skills you specify. Here's a quick guide on how you can request a custom test.
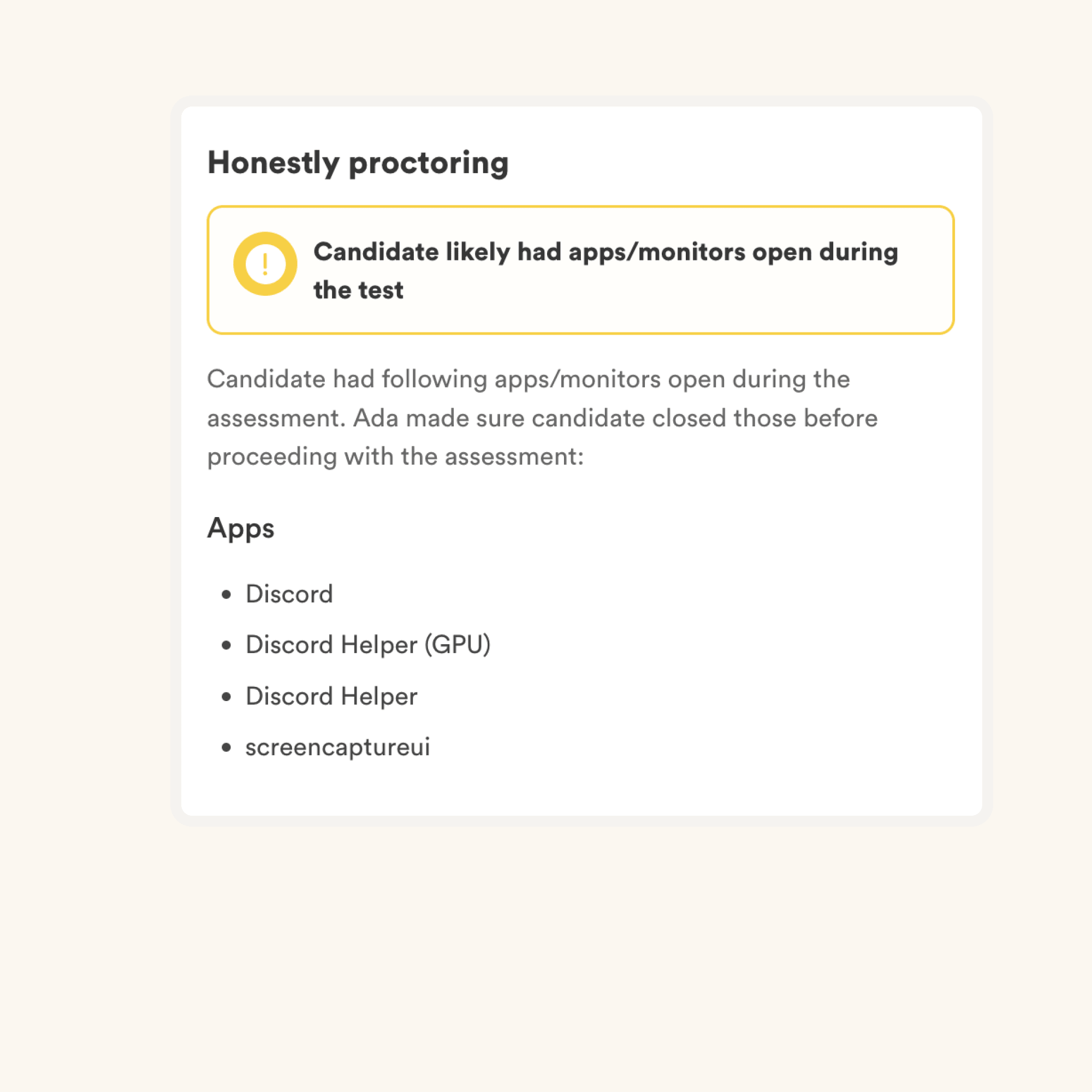
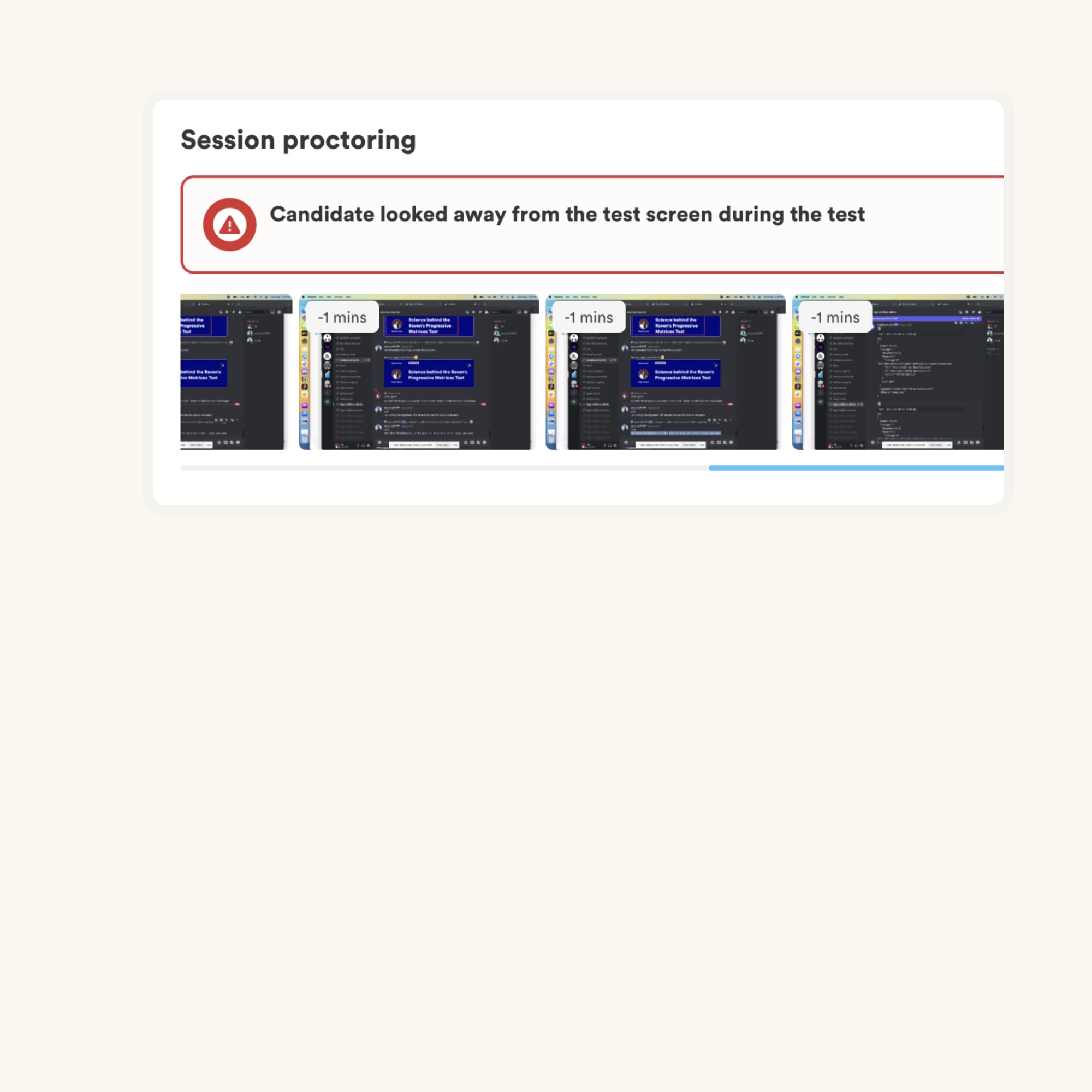
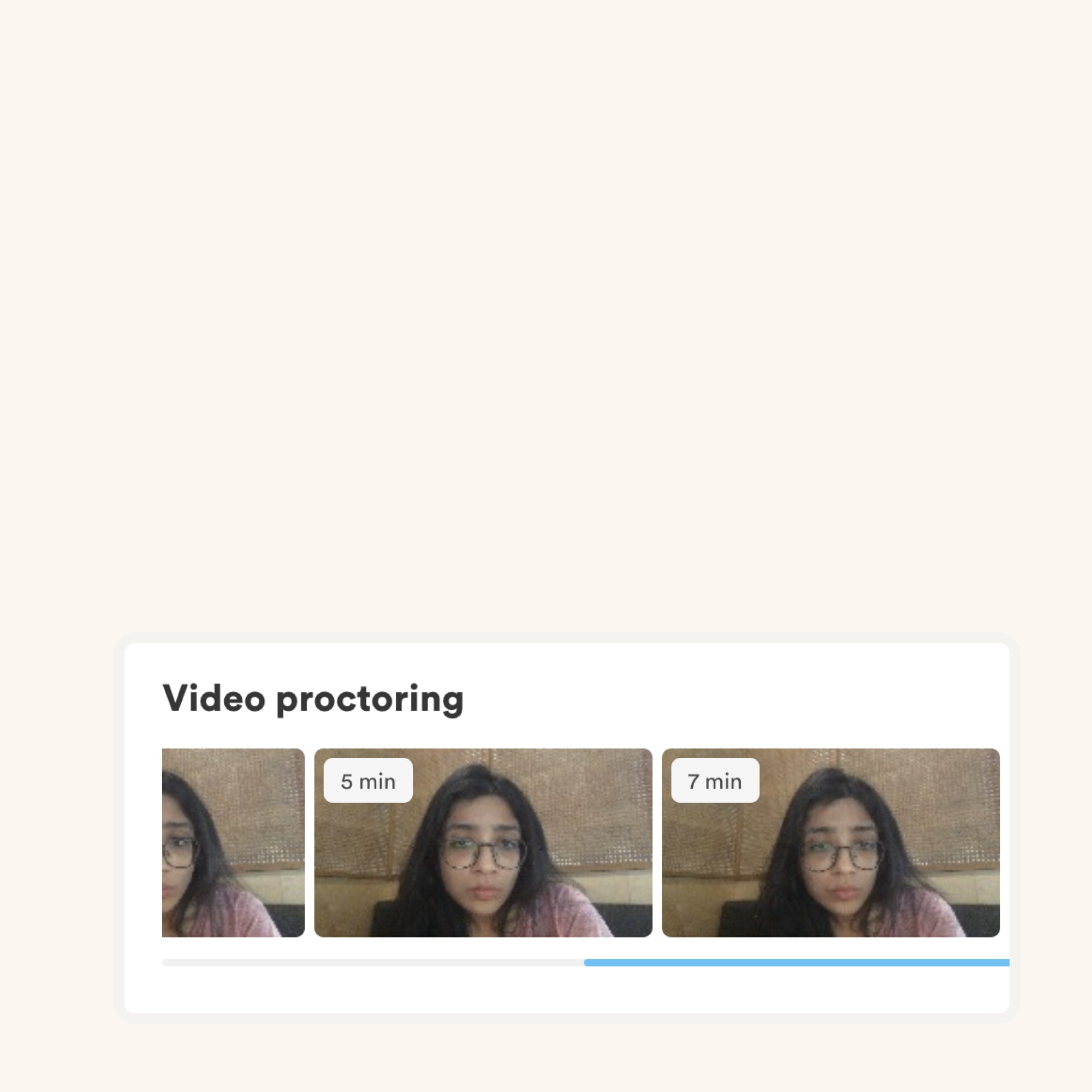
We have the following anti-cheating features in place:
Read more about the proctoring features.
The primary thing to keep in mind is that an assessment is an elimination tool, not a selection tool. A skills assessment is optimized to help you eliminate candidates who are not technically qualified for the role, it is not optimized to help you find the best candidate for the role. So the ideal way to use an assessment is to decide a threshold score (typically 55%, we help you benchmark) and invite all candidates who score above the threshold for the next rounds of interview.
Each Adaface assessment is customized to your job description/ ideal candidate persona (our subject matter experts will pick the right questions for your assessment from our library of 10000+ questions). This assessment can be customized for any experience level.
Yes, it makes it much easier for you to compare candidates. Options for MCQ questions and the order of questions are randomized. We have anti-cheating/ proctoring features in place. In our enterprise plan, we also have the option to create multiple versions of the same assessment with questions of similar difficulty levels.
No. Unfortunately, we do not support practice tests at the moment. However, you can use our sample questions for practice.
You can check out our pricing plans.
Yes, you can sign up for free and preview this test.
Here is a quick guide on how to request a custom assessment on Adaface.