Test Duration
~ 40 分钟
Difficulty Level
Moderate
Questions
- 4 Neural Networks MCQs
- 4 Deep Learning MCQs
- 4 机器学习 MCQs
- 4 Python MCQs
- 4 NumPy MCQs
Availability
Available on request
About the test:
神经网络测试评估了候选人对神经网络,深度学习,机器学习,Python,数据科学和Numpy的了解和理解。它包括多项选择问题,以评估理论知识和编码问题,以评估Python的编程技能。
Covered skills:
Test Duration
~ 40 分钟
Difficulty Level
Moderate
Questions
Availability
Available on request
The Neural Networks Test helps recruiters and hiring managers identify qualified candidates from a pool of resumes, and helps in taking objective hiring decisions. It reduces the administrative overhead of interviewing too many candidates and saves time by filtering out unqualified candidates at the first step of the hiring process.
The test screens for the following skills that hiring managers look for in candidates:
Traditional assessment tools use trick questions and puzzles for the screening, which creates a lot of frustration among candidates about having to go through irrelevant screening assessments.
The main reason we started Adaface is that traditional pre-employment assessment platforms are not a fair way for companies to evaluate candidates. At Adaface, our mission is to help companies find great candidates by assessing on-the-job skills required for a role.
Why we started AdafaceWe have a very high focus on the quality of questions that test for on-the-job skills. Every question is non-googleable and we have a very high bar for the level of subject matter experts we onboard to create these questions. We have crawlers to check if any of the questions are leaked online. If/ when a question gets leaked, we get an alert. We change the question for you & let you know.
How we design questions这些只是我们库中有10,000多个问题的一个小样本。关于此的实际问题 神经网络测试 将是不可行的.
| 🧐 Question | |||||
|---|---|---|---|---|---|
Medium Changed decision boundary | Try practice test | ||||
Medium CNN Architecture Tuning | Try practice test | ||||
Medium CNN for Imbalanced Image Dataset | Try practice test | ||||
Easy Gradient descent optimization | Try practice test | ||||
Medium Less complex decision tree model | Try practice test | ||||
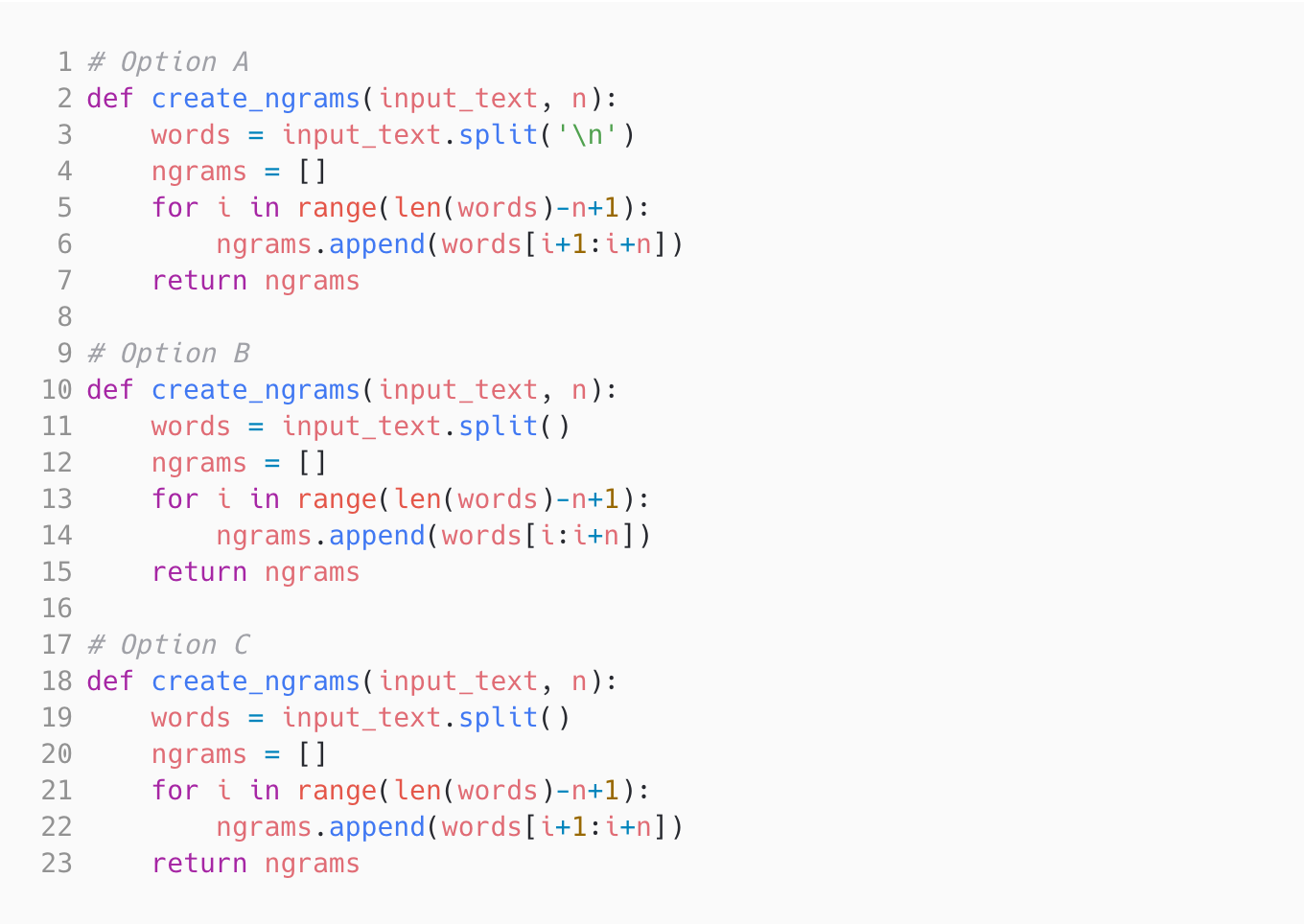
Easy n-gram generator | Try practice test | ||||
Easy Recommendation System Selection | Try practice test | ||||
Easy Sensitivity and Specificity | Try practice test | ||||
Medium ZeroDivisionError and IndexError | Try practice test | ||||
Medium Session | Try practice test | ||||
Medium Max Code | Try practice test | ||||
Medium Recursive Function | Try practice test | ||||
Medium Stacking problem | Try practice test | ||||
Medium Array Manipulation and Summation | Try practice test | ||||
Medium Matrix Eigenvalues and Diagonalization | Try practice test | ||||
| 🧐 Question | 🔧 Skill | ||
|---|---|---|---|
Medium Changed decision boundary | 2 mins Deep Learning | Try practice test | |
Medium CNN Architecture Tuning | 3 mins Deep Learning | Try practice test | |
Medium CNN for Imbalanced Image Dataset | 3 mins Deep Learning | Try practice test | |
Easy Gradient descent optimization | 2 mins Machine Learning | Try practice test | |
Medium Less complex decision tree model | 2 mins Machine Learning | Try practice test | |
Easy n-gram generator | 2 mins Machine Learning | Try practice test | |
Easy Recommendation System Selection | 2 mins Machine Learning | Try practice test | |
Easy Sensitivity and Specificity | 2 mins Machine Learning | Try practice test | |
Medium ZeroDivisionError and IndexError | 2 mins Python | Try practice test | |
Medium Session | 2 mins Python | Try practice test | |
Medium Max Code | 2 mins Python | Try practice test | |
Medium Recursive Function | 3 mins Python | Try practice test | |
Medium Stacking problem | 4 mins Python | Try practice test | |
Medium Array Manipulation and Summation | 2 mins NumPy | Try practice test | |
Medium Matrix Eigenvalues and Diagonalization | 3 mins NumPy | Try practice test |
| 🧐 Question | 🔧 Skill | 💪 Difficulty | ⌛ Time | ||
|---|---|---|---|---|---|
Changed decision boundary | Deep Learning | Medium | 2 mins | Try practice test | |
CNN Architecture Tuning | Deep Learning | Medium | 3 mins | Try practice test | |
CNN for Imbalanced Image Dataset | Deep Learning | Medium | 3 mins | Try practice test | |
Gradient descent optimization | Machine Learning | Easy | 2 mins | Try practice test | |
Less complex decision tree model | Machine Learning | Medium | 2 mins | Try practice test | |
n-gram generator | Machine Learning | Easy | 2 mins | Try practice test | |
Recommendation System Selection | Machine Learning | Easy | 2 mins | Try practice test | |
Sensitivity and Specificity | Machine Learning | Easy | 2 mins | Try practice test | |
ZeroDivisionError and IndexError | Python | Medium | 2 mins | Try practice test | |
Session | Python | Medium | 2 mins | Try practice test | |
Max Code | Python | Medium | 2 mins | Try practice test | |
Recursive Function | Python | Medium | 3 mins | Try practice test | |
Stacking problem | Python | Medium | 4 mins | Try practice test | |
Array Manipulation and Summation | NumPy | Medium | 2 mins | Try practice test | |
Matrix Eigenvalues and Diagonalization | NumPy | Medium | 3 mins | Try practice test |
借助 Adaface,我们能够将初步筛选流程优化达 75% 以上,为招聘经理和我们的人才招聘团队节省了宝贵的时间!
Brandon Lee, 人事主管, Love, Bonito
The most important thing while implementing the pre-employment 神经网络测试 in your hiring process is that it is an elimination tool, not a selection tool. In other words: you want to use the test to eliminate the candidates who do poorly on the test, not to select the candidates who come out at the top. While they are super valuable, pre-employment tests do not paint the entire picture of a candidate’s abilities, knowledge, and motivations. Multiple easy questions are more predictive of a candidate's ability than fewer hard questions. Harder questions are often "trick" based questions, which do not provide any meaningful signal about the candidate's skillset.
Science behind Adaface testsEmail invites: You can send candidates an email invite to the 神经网络测试 from your dashboard by entering their email address.
Public link: You can create a public link for each test that you can share with candidates.
API or integrations: You can invite candidates directly from your ATS by using our pre-built integrations with popular ATS systems or building a custom integration with your in-house ATS.
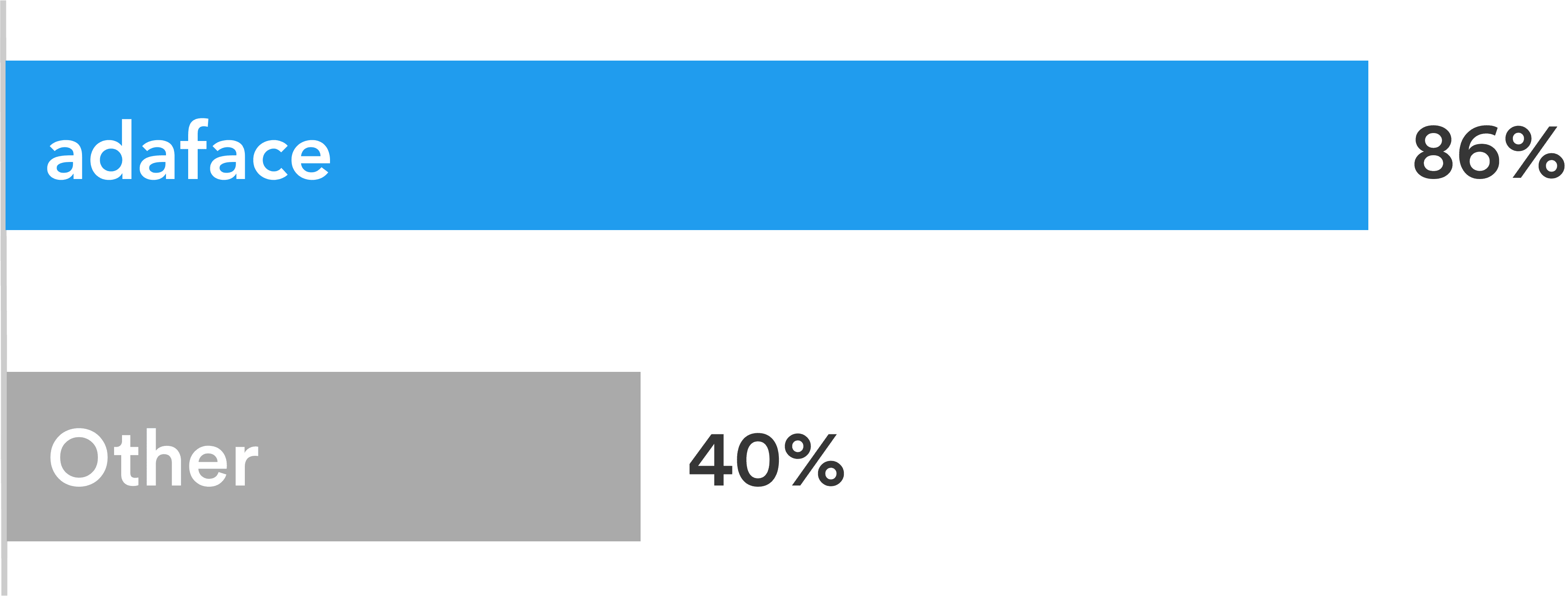
Adaface tests are conversational, low-stress, and take just 25-40 mins to complete.
This is why Adaface has the highest test-completion rate (86%), which is more than 2x better than traditional assessments.
ChatGPT protection
Screen proctoring
Plagiarism detection
Non-googleable questions
User authentication
IP proctoring
Web proctoring
Webcam proctoring
Full screen proctoring
Copy paste protection
招聘经理认为,通过小组面试中提出的技术问题,他们能够判断哪些候选人得分更高,并与得分较差的候选人区分开来。他们是 非常满意 通过 Adaface 筛选入围的候选人的质量。
是的,一点没错。自定义评估是根据您的职位描述进行的,并将包括有关您指定的所有必备技能的问题。
我们具有以下反交易功能:
阅读有关[Proctoring功能](https://www.adaface.com/proctoring)的更多信息。
要记住的主要问题是评估是消除工具,而不是选择工具。优化了技能评估,以帮助您消除在技术上没有资格担任该角色的候选人,它没有进行优化以帮助您找到该角色的最佳候选人。因此,使用评估的理想方法是确定阈值分数(通常为55%,我们为您提供基准测试),并邀请所有在下一轮面试中得分高于门槛的候选人。
每个ADAFACE评估都是为您的职位描述/理想候选角色定制的(我们的主题专家将从我们的10000多个问题的图书馆中选择正确的问题)。可以为任何经验级别定制此评估。
是的,这使您比较候选人变得容易得多。 MCQ问题的选项和问题顺序是随机的。我们有[抗欺骗/策略](https://www.adaface.com/proctoring)功能。在我们的企业计划中,我们还可以选择使用类似难度级别的问题创建多个版本的相同评估。
不,不幸的是,我们目前不支持实践测试。但是,您可以使用我们的[示例问题](https://www.adaface.com/questions)进行练习。
您可以查看我们的[定价计划](https://www.adaface.com/pricing/)。