Habilidades requeridas para un Desarrollador de Spark y cómo evaluarlas
Los desarrolladores de Spark son responsables de procesar grandes conjuntos de datos y garantizar que los datos fluyan sin problemas a través de las diversas etapas de las tuberías de datos. Trabajan con Apache Spark, un potente motor de procesamiento de código abierto, para gestionar las tareas de big data de forma eficiente y eficaz.
Las habilidades requeridas para un desarrollador de Spark incluyen dominio de lenguajes de programación como Scala o Python, una comprensión profunda de la computación distribuida y experiencia con herramientas y frameworks de big data. Además, la capacidad de resolución de problemas y unas sólidas habilidades analíticas son cruciales para el éxito en este puesto.
Los candidatos pueden escribir estas habilidades en sus currículums, pero no se pueden verificar sin pruebas de habilidades de desarrollador de Spark en el puesto de trabajo.
En esta publicación, exploraremos 8 habilidades esenciales de desarrollador de Spark, 9 habilidades secundarias y cómo evaluarlas para que pueda tomar decisiones de contratación informadas.
8 habilidades y rasgos fundamentales de los desarrolladores de Spark
9 habilidades y rasgos secundarios de los desarrolladores de Spark
Cómo evaluar las habilidades y rasgos de los desarrolladores de Spark
Resumen: Las 8 habilidades clave de los desarrolladores de Spark y cómo evaluarlas
Evalúe y contrate a los mejores desarrolladores de Spark con Adaface
Preguntas frecuentes sobre las habilidades de los desarrolladores de Spark
8 habilidades y rasgos fundamentales de los desarrolladores de Spark
Las mejores habilidades para los desarrolladores de Spark incluyen Apache Spark, Programación Scala, Modelado de datos, Ecosistema Hadoop, SQL y DataFrames, Ajuste del rendimiento, Datos de streaming y Machine Learning.
Profundicemos en los detalles examinando las 8 habilidades esenciales de un desarrollador de Spark.
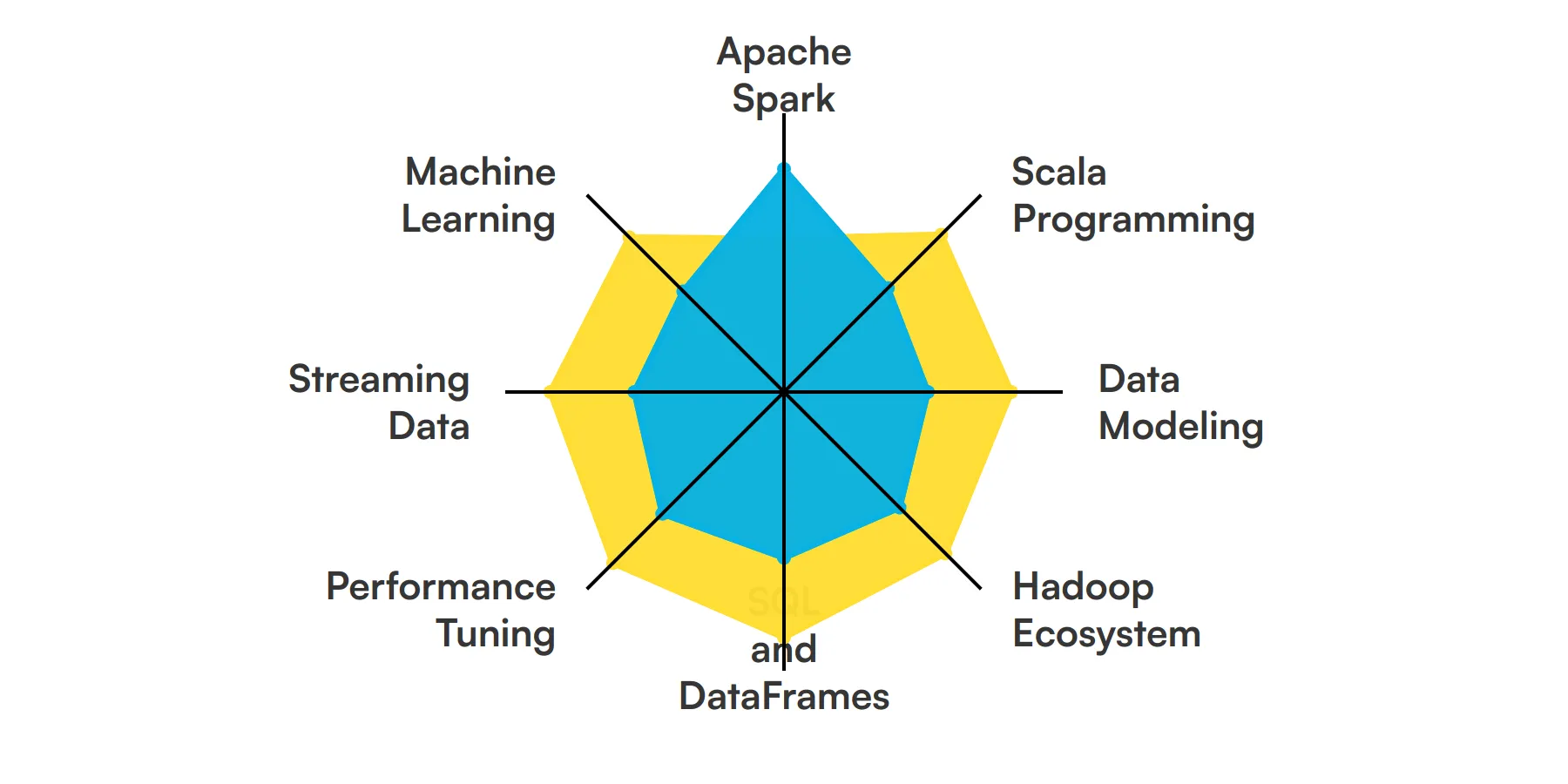
Apache Spark
Apache Spark es un motor de análisis unificado para el procesamiento de datos a gran escala. Un desarrollador de Spark utiliza esta herramienta para procesar conjuntos de datos vastos rápidamente utilizando las capacidades de computación en memoria de Spark. Esta habilidad es fundamental para manejar tareas de procesamiento de datos por lotes y en tiempo real de manera eficiente.
Para obtener más información, consulta nuestra guía para escribir una Descripción del puesto de desarrollador de Spark.
Programación Scala
Scala es a menudo el lenguaje de elección para las aplicaciones de Spark debido a sus características de programación funcional y su compatibilidad perfecta con Spark. Los desarrolladores utilizan Scala para escribir algoritmos concisos y complejos que se ejecutan en Spark, aprovechando su capacidad para manejar datos inmutables y concurrencia.
Modelado de Datos
Comprender las estructuras de datos y diseñar esquemas es crucial para un desarrollador de Spark. Esta habilidad implica organizar los datos de manera que se optimice el procesamiento en entornos Spark, lo cual es crucial para la manipulación y recuperación de datos efectivas en aplicaciones analíticas.
Consulta nuestra guía para obtener una lista completa de preguntas de entrevista.
Ecosistema Hadoop
El conocimiento del ecosistema Hadoop, incluyendo HDFS, YARN y MapReduce, es importante ya que Spark a menudo se ejecuta sobre Hadoop. Esta habilidad ayuda a administrar el almacenamiento de datos y la asignación de recursos para los trabajos de Spark, asegurando un rendimiento óptimo.
SQL y DataFrames
La competencia en SQL y el uso de Spark DataFrames es esencial para realizar análisis de datos complejos. Los desarrolladores de Spark aprovechan SQL para el procesamiento de datos estructurados y DataFrames para la manipulación y consulta eficientes de datos dentro de las aplicaciones Spark.
Para obtener más información, consulta nuestra guía sobre cómo redactar una descripción de trabajo de desarrollador SQL.
Ajuste del rendimiento
Un desarrollador de Spark debe ser experto en el ajuste de aplicaciones Spark para mejorar el rendimiento. Esto incluye optimizar las configuraciones, administrar el uso de la memoria y ajustar la serialización de datos y la partición de tareas para reducir el tiempo de procesamiento y el consumo de recursos.
Datos de transmisión
El manejo de datos de transmisión utilizando Spark Streaming o Structured Streaming es una habilidad clave. Los desarrolladores lo utilizan para construir aplicaciones de transmisión escalables y tolerantes a fallos que procesan datos en tiempo real, lo cual es crucial para las tareas analíticas urgentes.
Aprendizaje Automático
Utilizar MLlib de Spark para tareas de aprendizaje automático es otra habilidad importante. Esto implica crear modelos de aprendizaje automático escalables directamente dentro de Spark, lo cual es esencial para los desarrolladores que trabajan en proyectos de análisis predictivo y minería de datos.
Consulta nuestra guía para obtener una lista completa de preguntas de entrevista.
9 habilidades y rasgos secundarios de un desarrollador de Spark
Las mejores habilidades para los desarrolladores de Spark incluyen Programación Java, Programación Python, Plataformas en la nube, Contenedorización, Control de versiones Git, Bases de datos NoSQL, Visualización de datos, Sistemas Linux y Seguridad de datos.
Profundicemos en los detalles examinando las 9 habilidades secundarias de un desarrollador de Spark.
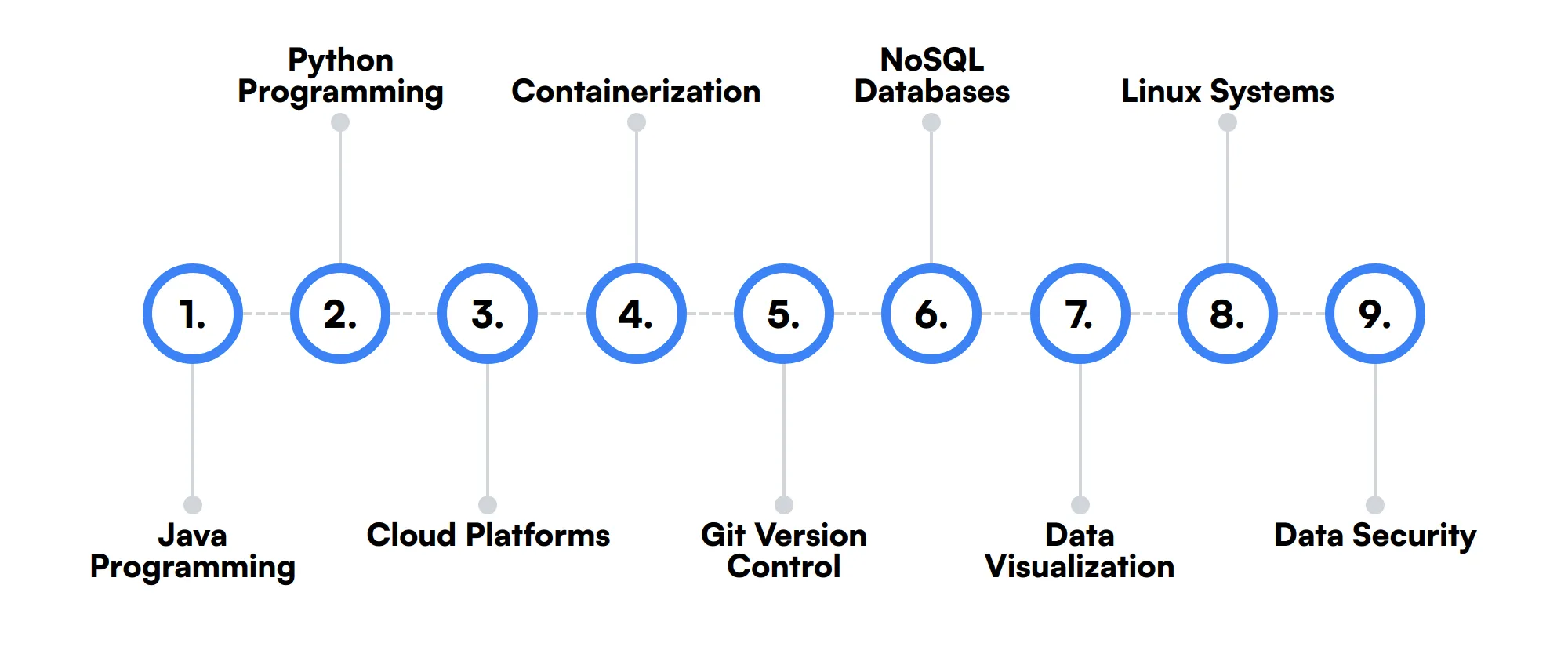
Programación Java
Si bien Scala es preferido, Java también se usa comúnmente con Spark. La familiaridad de Java y sus extensas bibliotecas lo convierten en una opción práctica para el desarrollo de Spark en entornos donde la experiencia en Java es prevalente.
Programación Python
Python es popular en la comunidad de ciencia de datos y es compatible con Spark a través de PySpark. Se utiliza para la creación rápida de prototipos de aplicaciones Spark y para integrar algoritmos de aprendizaje automático con facilidad.
Plataformas en la nube
La familiaridad con los servicios en la nube como AWS, Azure o GCP es beneficiosa, ya que muchos despliegues de Spark se están trasladando a la nube. Esto implica la gestión de clústeres de Spark en entornos en la nube y la optimización del almacenamiento de datos y los recursos informáticos.
Contenedorización
El conocimiento de Docker y Kubernetes ayuda a desplegar Spark dentro de contenedores, proporcionando escalabilidad y facilidad de despliegue en varios entornos, lo cual es cada vez más común en las arquitecturas de datos modernas.
Control de versiones Git
La competencia en Git para el control de versiones es necesaria para gestionar las bases de código de las aplicaciones Spark, especialmente en entornos colaborativos y de integración continua.
Bases de datos NoSQL
La comprensión de las bases de datos NoSQL como Cassandra o MongoDB es útil para los desarrolladores de Spark cuando se trata de datos no estructurados o cuando se requiere un rendimiento y una escalabilidad más allá de las bases de datos relacionales tradicionales.
Visualización de datos
Las habilidades en herramientas y bibliotecas de visualización de datos pueden mejorar la capacidad de presentar los datos procesados por Spark de una manera visualmente atractiva e informativa, lo cual es crucial para la toma de decisiones basada en datos.
Sistemas Linux
La mayoría de los entornos Spark se ejecutan en Linux, por lo que la familiaridad con los sistemas operativos Linux y el scripting de shell puede ser muy útil para configurar y gestionar clústeres Spark.
Seguridad de datos
Comprender las prácticas de seguridad de datos relevantes para Spark, como el cifrado y el procesamiento seguro de datos, es importante para garantizar que los proyectos de análisis de datos cumplan con los estándares legales y éticos.
Cómo evaluar las habilidades y rasgos de un desarrollador de Spark
Evaluar las habilidades y rasgos de un desarrollador de Spark implica una comprensión matizada tanto de la destreza técnica como del ingenio analítico. Los desarrolladores de Spark son fundamentales para gestionar y analizar big data de manera eficiente, utilizando un conjunto de habilidades que van desde el dominio de Apache Spark hasta la experiencia en machine learning y modelado de datos. Identificar al candidato adecuado requiere una inmersión profunda en sus conocimientos prácticos y teóricos.
Los métodos tradicionales como la revisión de currículums y la realización de entrevistas pueden dar una idea del historial de un candidato, pero no revelan sus capacidades de resolución de problemas en tiempo real. Aquí es donde entran en juego las evaluaciones prácticas. Al incorporar evaluaciones de habilidades en su proceso de contratación, puede medir las habilidades prácticas de un candidato en programación Scala, ajuste de rendimiento y más.
Para una evaluación exhaustiva, considere usar las evaluaciones de Adaface, que están diseñadas para reflejar la complejidad y la naturaleza de las tareas relacionadas con Spark. Estas evaluaciones ayudan a optimizar el proceso de selección, asegurando que dedique tiempo solo a los candidatos más prometedores, reduciendo potencialmente su tiempo de selección en un 85%.
Veamos cómo evaluar las habilidades de los desarrolladores de Spark con estas 6 evaluaciones de talento.
Prueba en línea de Spark
Nuestra prueba en línea de Spark evalúa la capacidad de un candidato para trabajar con Apache Spark, un potente motor de procesamiento de código abierto para big data. Esta prueba está diseñada para evaluar las habilidades en la transformación de datos estructurados, la optimización de trabajos de Spark y el análisis de estructuras de gráficos.
La prueba cubre los fundamentos de Spark Core, el desarrollo y la ejecución de trabajos de Spark en Java, Scala y Python, RDDs, Spark SQL, Dataframes y Datasets, Spark Streaming y la ejecución de Spark en un clúster. También incluye algoritmos iterativos y de varias etapas, la optimización y la solución de problemas de los trabajos de Spark, y la biblioteca GraphX para el análisis de gráficos.
Los candidatos que se desempeñan bien demuestran competencia en la conversión de desafíos de big data en scripts de Spark, la optimización de trabajos mediante la partición y el almacenamiento en caché, y la migración de datos de diversas fuentes. También muestran fuertes habilidades en el procesamiento de datos en tiempo real y el análisis de gráficos.
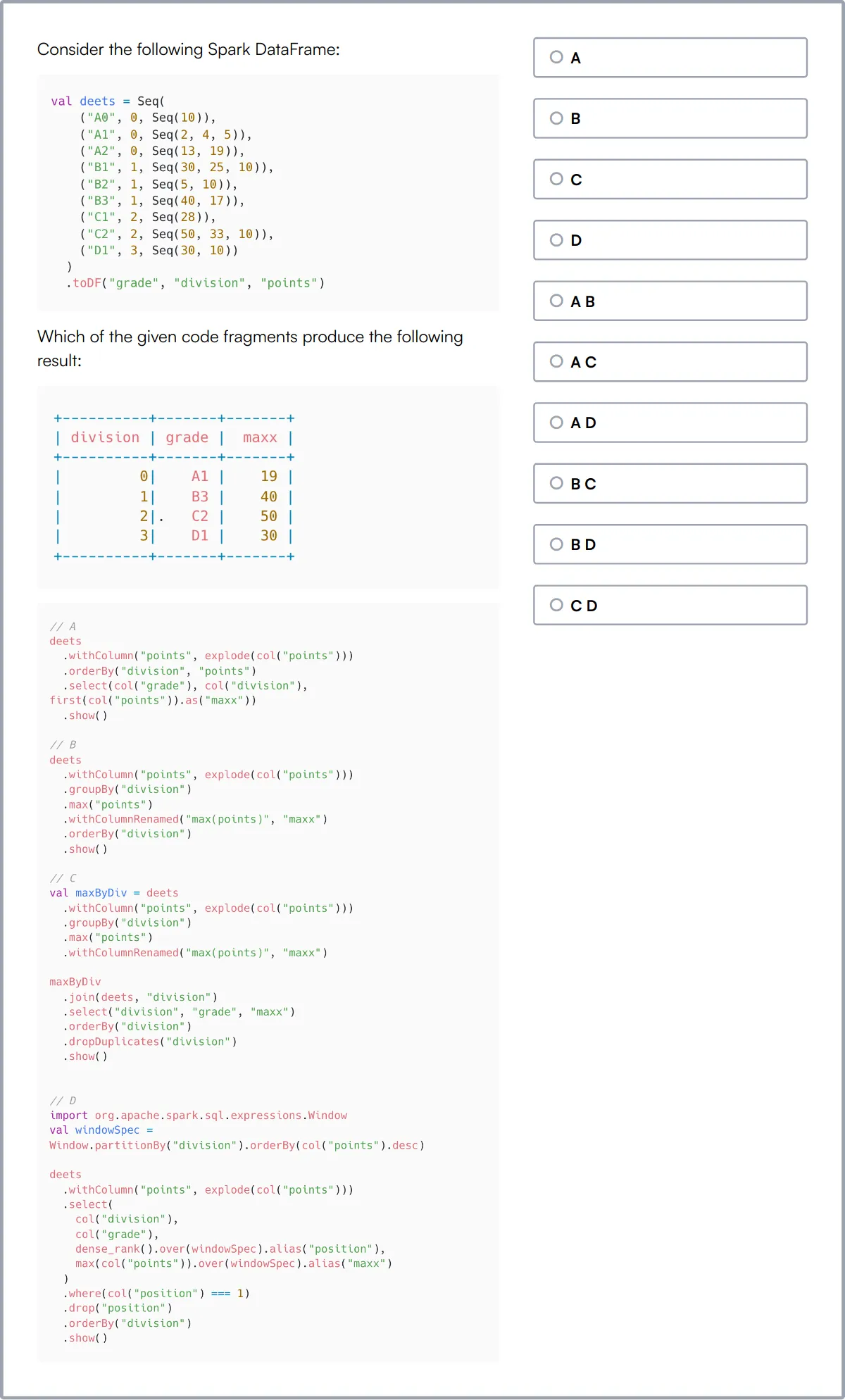
Prueba en línea de Scala
Nuestra Prueba en Línea de Scala evalúa la competencia de un candidato en el lenguaje de programación Scala, que combina paradigmas de programación orientada a objetos y funcional. Esta prueba es crucial para evaluar la capacidad de un candidato para diseñar y desarrollar aplicaciones escalables utilizando Scala.
La prueba cubre el lenguaje de programación Scala, programación funcional, programación orientada a objetos, colecciones, coincidencia de patrones, concurrencia y paralelismo, manejo de errores, inferencia de tipos, rasgos y mixins, funciones de orden superior y estructuras de datos inmutables. También incluye una pregunta de codificación para evaluar las habilidades prácticas de programación en Scala.
Los candidatos exitosos demuestran una sólida comprensión de los conceptos, la sintaxis y los principios de programación funcional de Scala. También muestran competencia en el uso de marcos de prueba de Scala y en el diseño de aplicaciones eficientes y escalables.
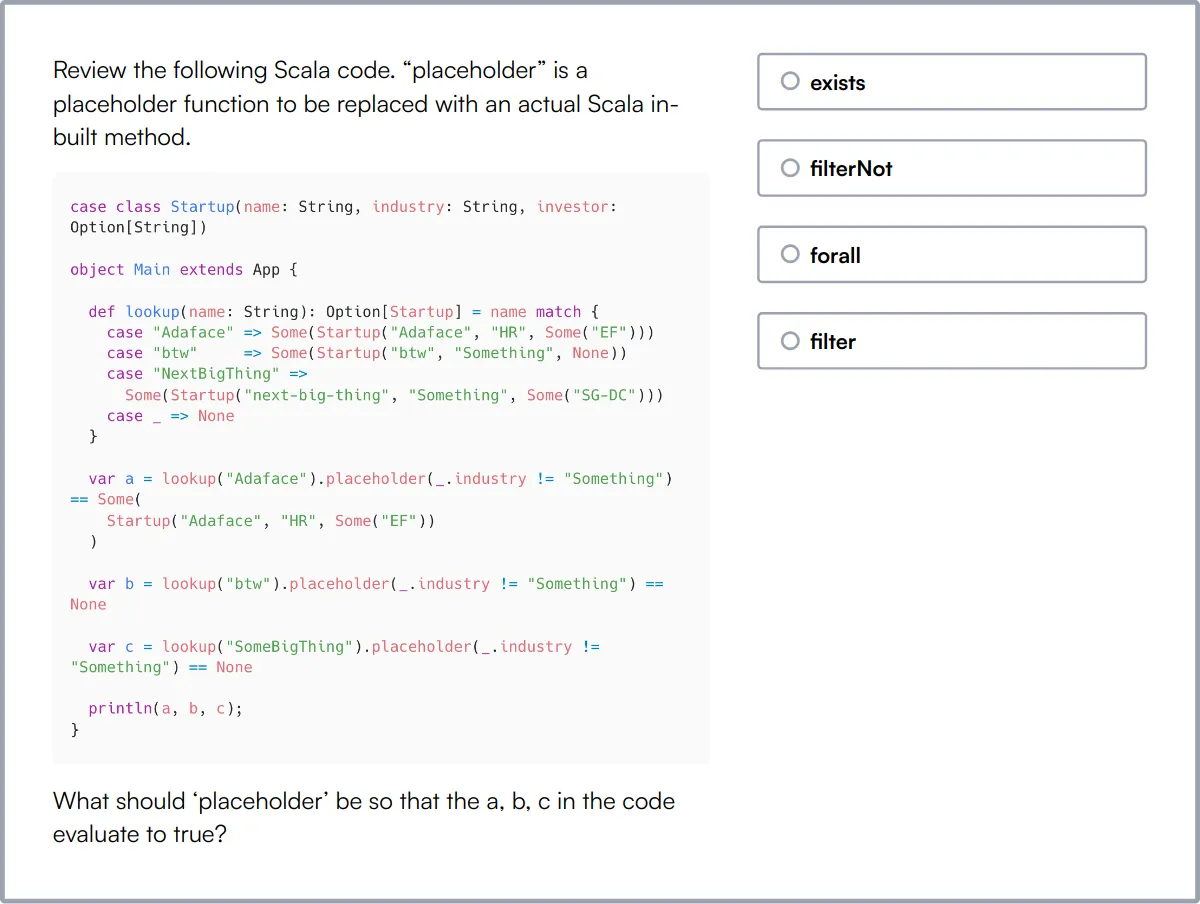
Prueba de habilidades de modelado de datos
Nuestro Test de Habilidades de Modelado de Datos evalúa el conocimiento y las habilidades de un candidato en el diseño de bases de datos y el modelado de datos. Esta prueba está diseñada para evaluar habilidades en la creación de esquemas de bases de datos eficientes y normalizados.
La prueba cubre modelado de datos, diseño de bases de datos, SQL, diagramas ER, normalización, esquema relacional, integridad de datos, mapeo de datos, validación de datos y transformación de datos. Incluye preguntas tanto sobre modelado de datos como sobre SQL para proporcionar una evaluación completa.
Los candidatos que se desempeñan bien demuestran competencia en el diseño de esquemas de bases de datos normalizados, asegurando la integridad de los datos y transformando los datos de manera efectiva. También muestran fuertes habilidades en SQL y almacenamiento de datos.
Prueba en Línea de Hadoop
Nuestro Test en Línea de Hadoop evalúa la capacidad de un candidato para trabajar con el ecosistema Hadoop, un marco para el almacenamiento y procesamiento distribuido de grandes conjuntos de datos. Esta prueba está diseñada para evaluar habilidades en la instalación y configuración de clústeres Hadoop y la ejecución de trabajos MapReduce optimizados.
La prueba cubre la instalación y configuración de clústeres Hadoop, la arquitectura central de Hadoop (HDFS, YARN, MapReduce), la escritura de consultas eficientes de Hive y Pig, la publicación de datos en clústeres, el manejo de datos en streaming, el trabajo con diferentes formatos de archivo y la resolución de problemas y monitoreo.
Los candidatos que se desempeñan bien demuestran competencia en la gestión de clústeres Hadoop, la escritura de consultas eficientes de análisis de datos y el manejo de datos de transmisión. También demuestran sólidas habilidades para solucionar problemas y monitorear entornos Hadoop.
Prueba en línea de SQL
Nuestra prueba en línea de SQL evalúa la capacidad de un candidato para diseñar y construir bases de datos relacionales y tablas desde cero. Esta prueba está diseñada para evaluar las habilidades en la escritura de consultas SQL eficientes y la gestión de operaciones de bases de datos.
La prueba cubre la creación de bases de datos, la creación y eliminación de tablas, operaciones CRUD en tablas, joins y subconsultas, expresiones y procedimientos condicionales, vistas, índices, funciones de cadena, funciones matemáticas y marcas de tiempo, bloqueos y transacciones, y escala y seguridad.
Los candidatos que se desempeñan bien demuestran competencia en el diseño de bases de datos relacionales, la escritura de consultas eficientes y la gestión de operaciones de bases de datos. También demuestran sólidas habilidades para optimizar consultas SQL y garantizar la seguridad de la base de datos.
Prueba en línea de Kafka
Nuestra prueba en línea de Kafka evalúa el conocimiento de un candidato sobre Apache Kafka, una plataforma de transmisión de eventos distribuida. Esta prueba está diseñada para evaluar las habilidades en el trabajo con colas de mensajes, el procesamiento de flujos y los sistemas distribuidos.
La prueba cubre offsets de Kafka, réplicas sincronizadas, clústeres de Kafka, sistemas distribuidos, transmisión de eventos, colas de mensajes, tuberías de datos, procesamiento de flujos, tolerancia a fallos, escalabilidad y replicación de datos.
Los candidatos que se desempeñan bien demuestran competencia en el diseño y desarrollo de sistemas de mensajería escalables y tolerantes a fallos. También demuestran sólidas habilidades en los flujos de trabajo de productores y consumidores de Kafka, particionamiento y replicación.
Resumen: Las 8 habilidades clave de un desarrollador de Spark y cómo evaluarlas
| Habilidad del desarrollador de Spark | Cómo evaluarlas |
|---|---|
| 1. Apache Spark | Evaluar la competencia en el procesamiento de grandes conjuntos de datos utilizando las funcionalidades principales de Spark. |
| 2. Programación Scala | Evaluar la capacidad de escribir y optimizar código en Scala para aplicaciones Spark. |
| 3. Modelado de datos | Verificar las habilidades en el diseño e implementación de modelos de datos para análisis. |
| 4. Ecosistema Hadoop | Medir la familiaridad con las herramientas de Hadoop y su integración con Spark. |
| 5. SQL y DataFrames | Medir la experiencia en la consulta y manipulación de datos utilizando SQL y DataFrames. |
| 6. Ajuste de rendimiento | Evaluar la capacidad de optimizar los trabajos de Spark para un mejor rendimiento. |
| 7. Datos de transmisión | Evaluar la experiencia en el manejo de flujos de datos en tiempo real con Spark Streaming. |
| 8. Aprendizaje automático | Verificar el conocimiento de la implementación de algoritmos de aprendizaje automático utilizando Spark MLlib. |
Prueba en línea de Spark
30 minutos | 15 preguntas de opción múltiple
La prueba en línea de Apache Spark evalúa la capacidad del candidato para transformar datos estructurados con la API RDD y SparkSQL (Conjuntos de datos y DataFrames), convertir desafíos de big data en scripts de Spark iterativos/de múltiples etapas, optimizar trabajos de Spark existentes utilizando particiones/caché y analizar estructuras de gráficos utilizando GraphX.
[
Probar la prueba en línea de Spark
](https://www.adaface.com/assessment-test/spark-online-test)
Preguntas frecuentes sobre las habilidades de un desarrollador de Spark
¿Qué habilidades son necesarias para un desarrollador de Spark?
Un desarrollador de Spark debe ser competente en Apache Spark, programación en Scala o Python, y estar familiarizado con el ecosistema Hadoop. También es importante tener habilidades en SQL, DataFrames y ajuste del rendimiento. El conocimiento de Java, el aprendizaje automático y la seguridad de datos añaden valor.
¿Cómo pueden los reclutadores evaluar la competencia de un candidato en Apache Spark?
Los reclutadores pueden evaluar la competencia en Apache Spark pidiendo a los candidatos que resuelvan problemas del mundo real utilizando Spark, revisando proyectos anteriores o realizando entrevistas técnicas que incluyan desafíos de codificación y preguntas basadas en escenarios.
¿Cuál es el papel de Scala en el desarrollo de Spark?
Scala se utiliza a menudo en el desarrollo de Spark debido a sus características de programación funcional y su perfecta integración con Spark, lo que permite un código más conciso y legible, lo cual es crucial para procesar grandes conjuntos de datos de manera eficiente.
¿Por qué es importante el conocimiento del ecosistema Hadoop para los desarrolladores de Spark?
Comprender el ecosistema Hadoop es importante para los desarrolladores de Spark porque Spark a menudo se implementa junto con componentes de Hadoop como HDFS para el almacenamiento y YARN para la gestión de recursos, lo que permite el procesamiento de datos escalable y distribuido.
¿Qué tan importantes son las habilidades de SQL para un desarrollador de Spark?
Las habilidades de SQL son importantes para un desarrollador de Spark, ya que permiten la manipulación de datos estructurados a través de Spark SQL y DataFrames, lo que simplifica las consultas de datos y puede mejorar el rendimiento de las aplicaciones de procesamiento de datos.
¿Qué deben buscar los reclutadores al evaluar el conocimiento en seguridad de datos para roles de Spark?
Los reclutadores deben buscar familiaridad con las prácticas de procesamiento de datos seguro, conocimiento de técnicas de encriptación y desencriptación, y experiencia con protocolos y herramientas de seguridad que protejan los datos tanto en tránsito como en reposo.
¿Cómo puede un candidato demostrar experiencia en la optimización del rendimiento en Spark?
Los candidatos pueden demostrar experiencia en la optimización del rendimiento discutiendo técnicas específicas que han utilizado para optimizar las aplicaciones Spark, como ajustar las configuraciones de Spark, ajustar la asignación de recursos y optimizar la serialización de datos y los formatos de almacenamiento.
¿Qué papel juega Python en el desarrollo de Spark?
Python se utiliza en el desarrollo de Spark por su simplicidad y legibilidad, lo que lo convierte en una opción popular para el análisis de datos y las tareas de aprendizaje automático dentro de los ecosistemas Spark. PySpark, la API de Python para Spark, permite a los desarrolladores aprovechar las capacidades de Spark utilizando Python.
Next posts
- 70 preguntas de entrevista para consultores funcionales de SAP para hacer a los candidatos
- 46 preguntas de entrevista para consultores SAP FICO para hacer a los candidatos
- 79 Preguntas de entrevista para arquitectos de información para contratar a los mejores talentos
- 60 preguntas de entrevista para Gerentes de Éxito del Cliente para hacer a tus candidatos
- 67 preguntas de entrevista para especialistas en SEO para contratar al mejor talento