Habilidades requeridas para un Ingeniero de Big Data y cómo evaluarlas
Los ingenieros de Big Data son los arquitectos de las tuberías e infraestructuras de datos. Diseñan, construyen y mantienen los sistemas que permiten a las organizaciones recopilar, almacenar y analizar grandes volúmenes de datos de forma eficiente y eficaz.
Las habilidades de ingeniería de Big Data incluyen dominio de lenguajes de programación como Python, Java y Scala, así como experiencia en frameworks de procesamiento de datos como Hadoop y Spark. Además, son esenciales para el éxito en este puesto habilidades en modelado de datos, gestión de bases de datos y plataformas en la nube.
Los candidatos pueden escribir estas habilidades en sus currículums, pero no puede verificarlas sin pruebas de habilidades de ingeniero de Big Data en el trabajo.
En este artículo, exploraremos 9 habilidades esenciales de ingeniero de Big Data, 10 habilidades secundarias y cómo evaluarlas para que pueda tomar decisiones de contratación informadas.
9 habilidades y rasgos fundamentales de los ingenieros de Big Data
10 habilidades y rasgos secundarios de los ingenieros de Big Data
Cómo evaluar las habilidades y rasgos de los ingenieros de Big Data
Resumen: Las 9 habilidades clave de los ingenieros de Big Data y cómo probarlas
Evalúe y contrate a los mejores ingenieros de Big Data con Adaface
Preguntas frecuentes sobre las habilidades de los ingenieros de Big Data
9 habilidades y rasgos fundamentales de los ingenieros de Big Data
Las mejores habilidades para los ingenieros de Big Data incluyen Lenguajes de programación, Almacenamiento de datos, Procesos ETL, Ecosistema Hadoop, Modelado de datos, SQL y NoSQL, Seguridad de datos, Plataformas en la nube y Visualización de datos.
Profundicemos en los detalles examinando las 9 habilidades esenciales de un Ingeniero de Big Data.
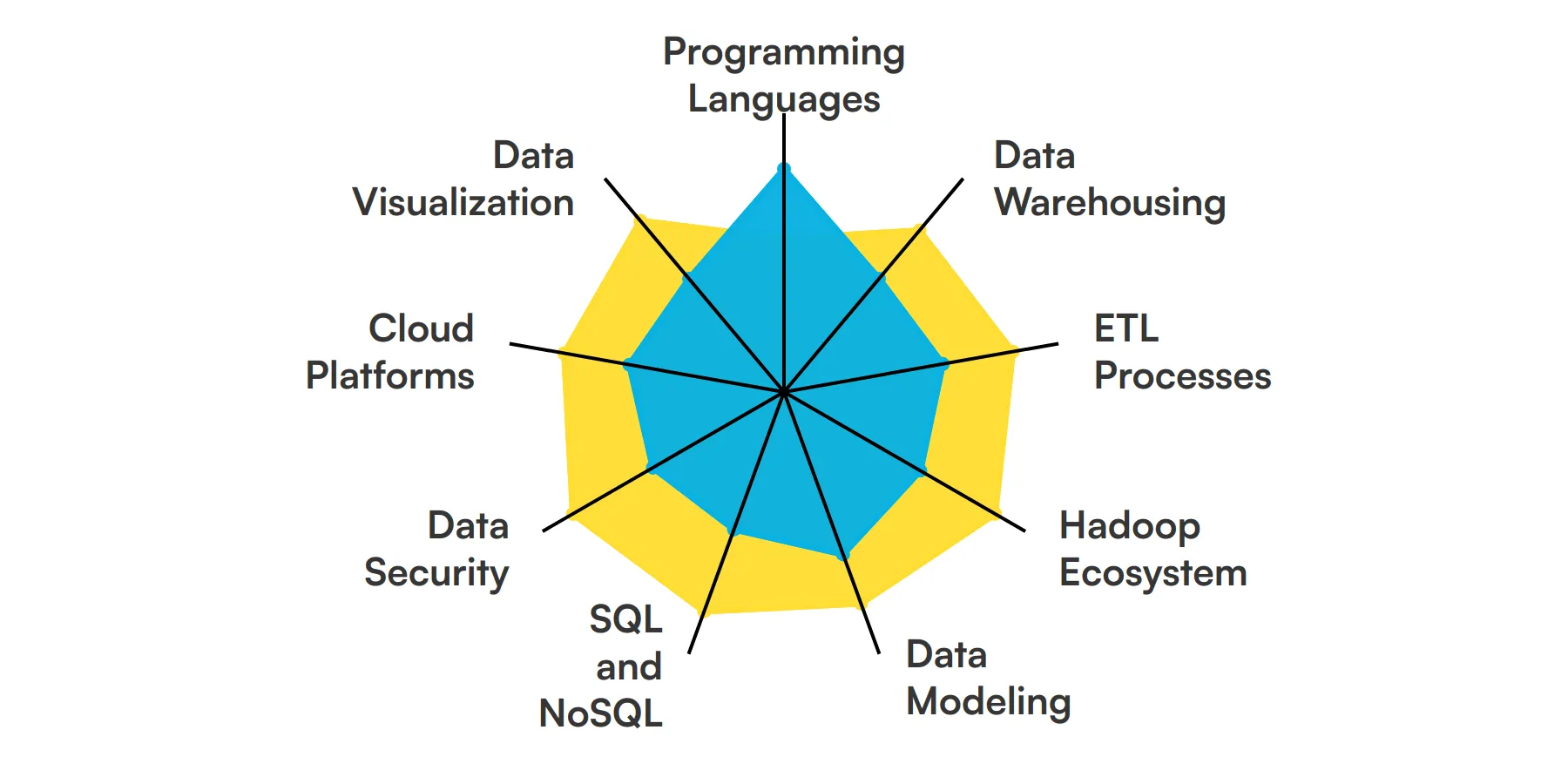
Lenguajes de Programación
Un Ingeniero de Big Data debe dominar lenguajes de programación como Java, Python y Scala. Estos lenguajes son esenciales para escribir scripts de procesamiento de datos y construir pipelines de datos. Ayudan a manipular grandes conjuntos de datos e integrar diversas fuentes de datos.
Almacenamiento de Datos (Data Warehousing)
El conocimiento de soluciones de almacenamiento de datos como Amazon Redshift, Google BigQuery y Snowflake es crucial. Estas herramientas ayudan a almacenar y gestionar grandes volúmenes de datos de manera eficiente. Un Ingeniero de Big Data utiliza estas plataformas para organizar y consultar datos para su análisis.
Consulta nuestra guía para obtener una lista completa de preguntas de entrevista.
Procesos ETL
Los procesos de Extracción, Transformación y Carga (ETL) son fundamentales para un Ingeniero de Big Data. Implican extraer datos de diversas fuentes, transformarlos a un formato utilizable y cargarlos en un data warehouse. Es necesario dominar herramientas ETL como Apache NiFi y Talend.
Ecosistema Hadoop
Entender el ecosistema Hadoop, incluyendo HDFS, MapReduce y YARN, es esencial. Estas herramientas se utilizan para el almacenamiento y procesamiento distribuido de grandes conjuntos de datos. Un Ingeniero de Big Data aprovecha Hadoop para manejar eficientemente las cargas de trabajo de big data.
Para obtener más información, consulta nuestra guía para redactar una Descripción del puesto de trabajo de desarrollador de Hadoop.
Modelado de datos
Las habilidades de modelado de datos son importantes para diseñar y estructurar bases de datos. Un ingeniero de Big Data utiliza el modelado de datos para crear esquemas que admitan la recuperación y el almacenamiento eficientes de datos. Esto asegura que la arquitectura de datos se alinee con los requisitos del negocio.
SQL y NoSQL
Es necesaria la competencia en bases de datos SQL y NoSQL. Las bases de datos SQL como MySQL y PostgreSQL se utilizan para datos estructurados, mientras que las bases de datos NoSQL como MongoDB y Cassandra manejan datos no estructurados. Un ingeniero de Big Data debe saber cuándo usar cada tipo.
Consulta nuestra guía para obtener una lista completa de preguntas de la entrevista.
Seguridad de datos
Garantizar la seguridad y el cumplimiento de los datos es una responsabilidad clave. Un ingeniero de Big Data debe implementar el cifrado, los controles de acceso y otras medidas de seguridad para proteger los datos confidenciales. También es importante comprender regulaciones como GDPR y HIPAA.
Plataformas en la nube
La familiaridad con plataformas en la nube como AWS, Azure y Google Cloud es esencial. Estas plataformas ofrecen recursos escalables para el procesamiento y el almacenamiento de big data. Un ingeniero de Big Data utiliza servicios en la nube para implementar y administrar soluciones de datos.
Para obtener más información, consulta nuestra guía para redactar una Descripción del puesto de ingeniero de la nube.
Visualización de datos
Herramientas de visualización de datos como Tableau, Power BI y D3.js son importantes para presentar información de datos. Un ingeniero de Big Data utiliza estas herramientas para crear paneles e informes que ayudan a las partes interesadas a comprender las tendencias y patrones de datos complejos.
10 habilidades y rasgos secundarios de un ingeniero de Big Data
Las mejores habilidades para los ingenieros de Big Data incluyen Aprendizaje automático, Procesamiento de flujo, Lenguajes de scripting, Gobierno de datos, Integración de API, Prácticas de DevOps, Limpieza de datos, Control de versiones, Perspicacia empresarial y Lagos de datos.
Profundicemos en los detalles examinando las 10 habilidades secundarias de un ingeniero de Big Data.
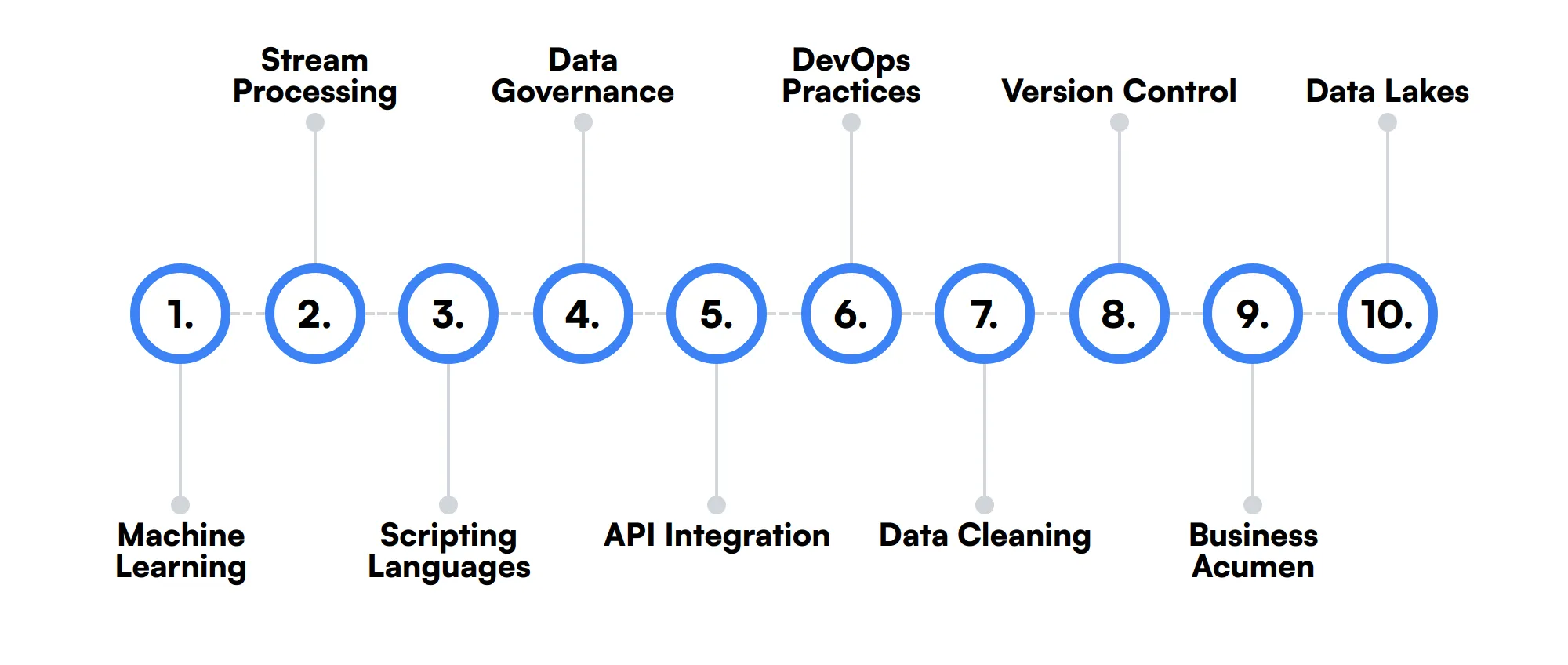
Aprendizaje automático
El conocimiento de algoritmos y frameworks de aprendizaje automático como TensorFlow y PyTorch puede ser beneficioso. Un Ingeniero de Big Data podría usar estas habilidades para construir modelos predictivos y mejorar las capacidades de análisis de datos.
Procesamiento de Flujos
La experiencia con herramientas de procesamiento de flujos como Apache Kafka y Apache Flink es útil. Estas herramientas permiten el procesamiento de datos en tiempo real, lo cual es crucial para aplicaciones que requieren información de datos inmediata.
Lenguajes de Scripting
La competencia en lenguajes de scripting como Bash y Perl puede ayudar a automatizar tareas repetitivas. Un Ingeniero de Big Data utiliza estos scripts para optimizar los flujos de trabajo de procesamiento de datos y el mantenimiento del sistema.
Gobernanza de Datos
La comprensión de los principios de gobernanza de datos ayuda a mantener la calidad e integridad de los datos. Un Ingeniero de Big Data asegura que se sigan las políticas y estándares de datos, lo cual es importante para una gestión de datos fiable.
Integración de API
Las habilidades en la integración de API son útiles para conectar diferentes fuentes de datos y servicios. Un Ingeniero de Big Data a menudo trabaja con APIs para obtener datos de sistemas externos e integrarlos en la tubería de datos.
Prácticas de DevOps
La familiaridad con las prácticas de DevOps y herramientas como Docker y Kubernetes puede ser ventajosa. Estas habilidades ayudan a desplegar y gestionar aplicaciones de big data de manera escalable y eficiente.
Limpieza de Datos
Las habilidades de limpieza de datos son importantes para garantizar la precisión y consistencia de los datos. Un Ingeniero de Big Data dedica una cantidad significativa de tiempo a limpiar y preprocesar datos para que sean adecuados para el análisis.
Control de Versiones
El conocimiento de sistemas de control de versiones como Git es importante para gestionar los cambios de código. Un Ingeniero de Big Data utiliza el control de versiones para colaborar con los miembros del equipo y mantener un historial de las modificaciones del código.
Perspicacia para los negocios
La comprensión del contexto y los requisitos del negocio ayuda a diseñar soluciones de datos relevantes. Un Ingeniero de Big Data necesita alinear los proyectos de datos con los objetivos del negocio para ofrecer información procesable.
Lagos de datos
La experiencia con lagos de datos, como los construidos en AWS S3 o Azure Data Lake, es beneficiosa. Estos repositorios de almacenamiento permiten a un Ingeniero de Big Data almacenar grandes cantidades de datos en bruto en su formato nativo.
Cómo evaluar las habilidades y rasgos de un Ingeniero de Big Data
Evaluar las habilidades y los rasgos de un Ingeniero de Big Data puede ser una tarea desafiante, dada la amplia gama de conocimientos técnicos requeridos. Desde lenguajes de programación y almacenamiento de datos hasta procesos ETL y el ecosistema Hadoop, un Ingeniero de Big Data debe ser experto en varios dominios para manejar las complejidades de la gestión de datos a gran escala.
Los currículums y las certificaciones pueden proporcionar una instantánea de los antecedentes de un candidato, pero a menudo no logran demostrar la competencia y la capacidad de resolución de problemas en el mundo real. Las evaluaciones basadas en habilidades son una forma fiable de medir las verdaderas capacidades de un candidato y su adecuación a sus necesidades específicas.
Por ejemplo, es posible que deba evaluar su experiencia en bases de datos SQL y NoSQL, modelado de datos y seguridad de datos. Además, a menudo es necesaria la familiaridad con las plataformas en la nube y las herramientas de visualización de datos. Las evaluaciones de Adaface pueden ayudarlo a lograr una calidad de contratación 2 veces mejorada al proporcionar pruebas personalizadas que se enfocan en estas áreas clave, asegurando que encuentre la opción correcta para su equipo.
Veamos cómo evaluar las habilidades de un ingeniero de Big Data con estas 6 evaluaciones de talento.
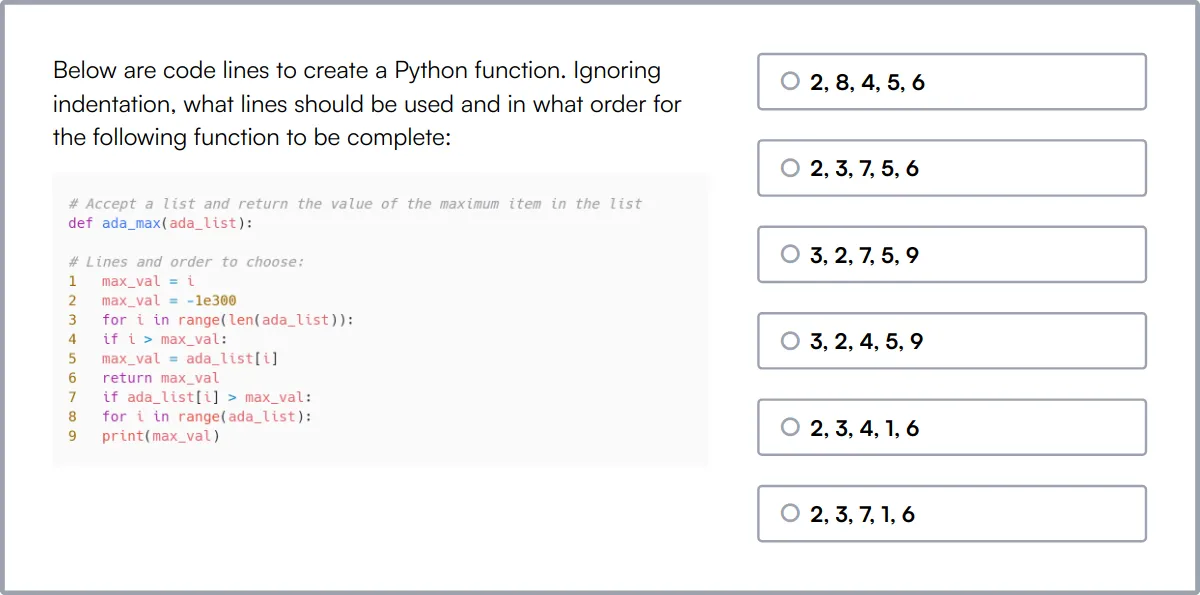
Prueba en línea de Python
Nuestra Prueba en línea de Python evalúa la competencia de un candidato en Python, cubriendo una amplia gama de temas, desde la sintaxis básica hasta conceptos complejos como la programación orientada a objetos y funcional.
La prueba evalúa su comprensión de las estructuras de datos de Python, el manejo de errores, las operaciones de archivos y la manipulación de bases de datos, lo que garantiza que los candidatos puedan manejar desafíos de codificación prácticos.
Los candidatos exitosos demuestran su capacidad para depurar de manera efectiva y escribir código optimizado utilizando las amplias bibliotecas y marcos de Python.
Prueba en línea de Data Warehouse
Nuestra Prueba en línea de Data Warehouse mide la experiencia de un candidato en almacenamiento de datos, incluidas las consultas SQL, los procesos ETL y el modelado de datos.
Esta prueba evalúa el conocimiento en conceptos básicos de SQL, fundamentos de almacenamiento de datos y fundamentos de ETL, lo que garantiza que los candidatos puedan diseñar y mantener soluciones de almacenamiento de datos eficientes.
Los candidatos que sobresalen en esta prueba son expertos en la creación y gestión de almacenes de datos escalables que soportan análisis de datos complejos.
Prueba en línea de Informatica
Nuestra Prueba en línea de Informatica se centra en la capacidad del candidato para usar Informatica PowerCenter para la integración de datos y los procesos ETL efectivos.
La prueba cubre el almacenamiento de datos, ETL, la integración de datos y el uso de las herramientas PowerCenter para gestionar las transformaciones y sincronizaciones de datos.
Los candidatos con altas puntuaciones son competentes en el diseño e implementación de tareas complejas de manejo de datos con Informatica, mejorando la calidad y accesibilidad de los datos.
Prueba en línea de Hadoop
Nuestra Prueba en línea de Hadoop evalúa a los candidatos en su capacidad para configurar y gestionar clústeres Hadoop, y para procesar grandes conjuntos de datos utilizando el ecosistema de Hadoop.
La prueba evalúa la arquitectura central de Hadoop, incluyendo HDFS, YARN y MapReduce, así como la capacidad de escribir consultas Hive y Pig para el análisis de datos.
Los candidatos proficientes en Hadoop pueden manejar eficazmente los desafíos de los big data, optimizando el procesamiento y el almacenamiento de datos en sistemas distribuidos.
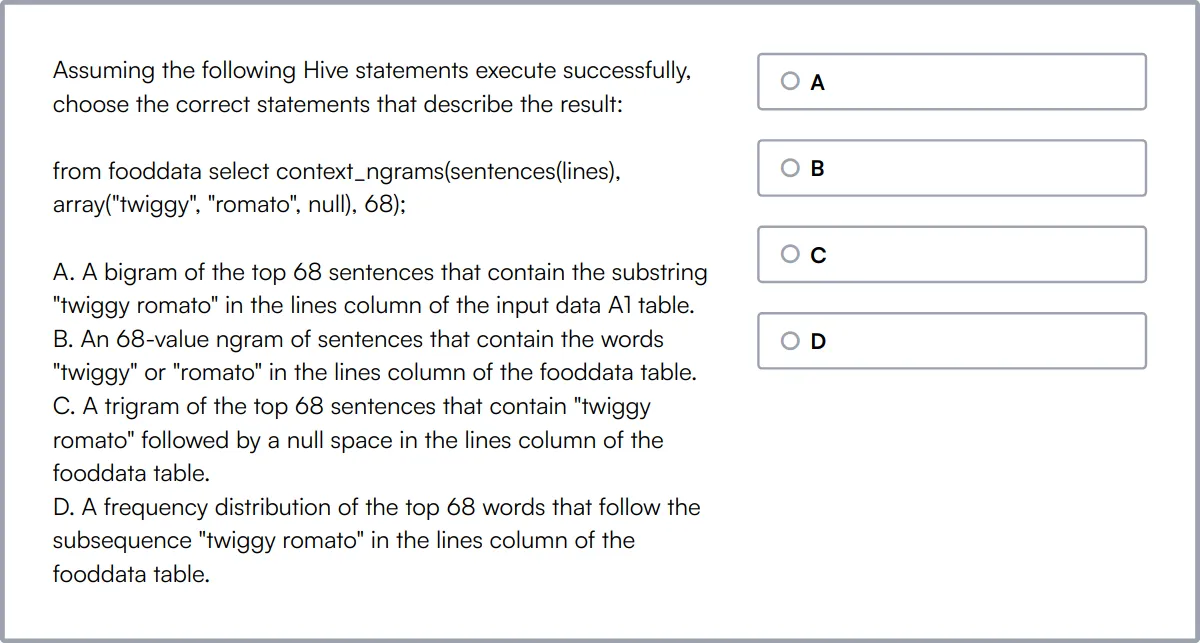
Test de Habilidades de Modelado de Datos
Nuestro Test de Habilidades de Modelado de Datos evalúa la capacidad de un candidato en el diseño de bases de datos e integridad de datos utilizando SQL, diagramas ER y técnicas de normalización.
Esta prueba evalúa habilidades en modelado de datos, diseño de esquemas relacionales y la implementación de estrategias de validación y transformación de datos.
Los candidatos capacitados pueden diseñar bases de datos que garanticen la precisión y eficiencia de los datos, lo cual es crucial para apoyar la inteligencia empresarial y los procesos de toma de decisiones.
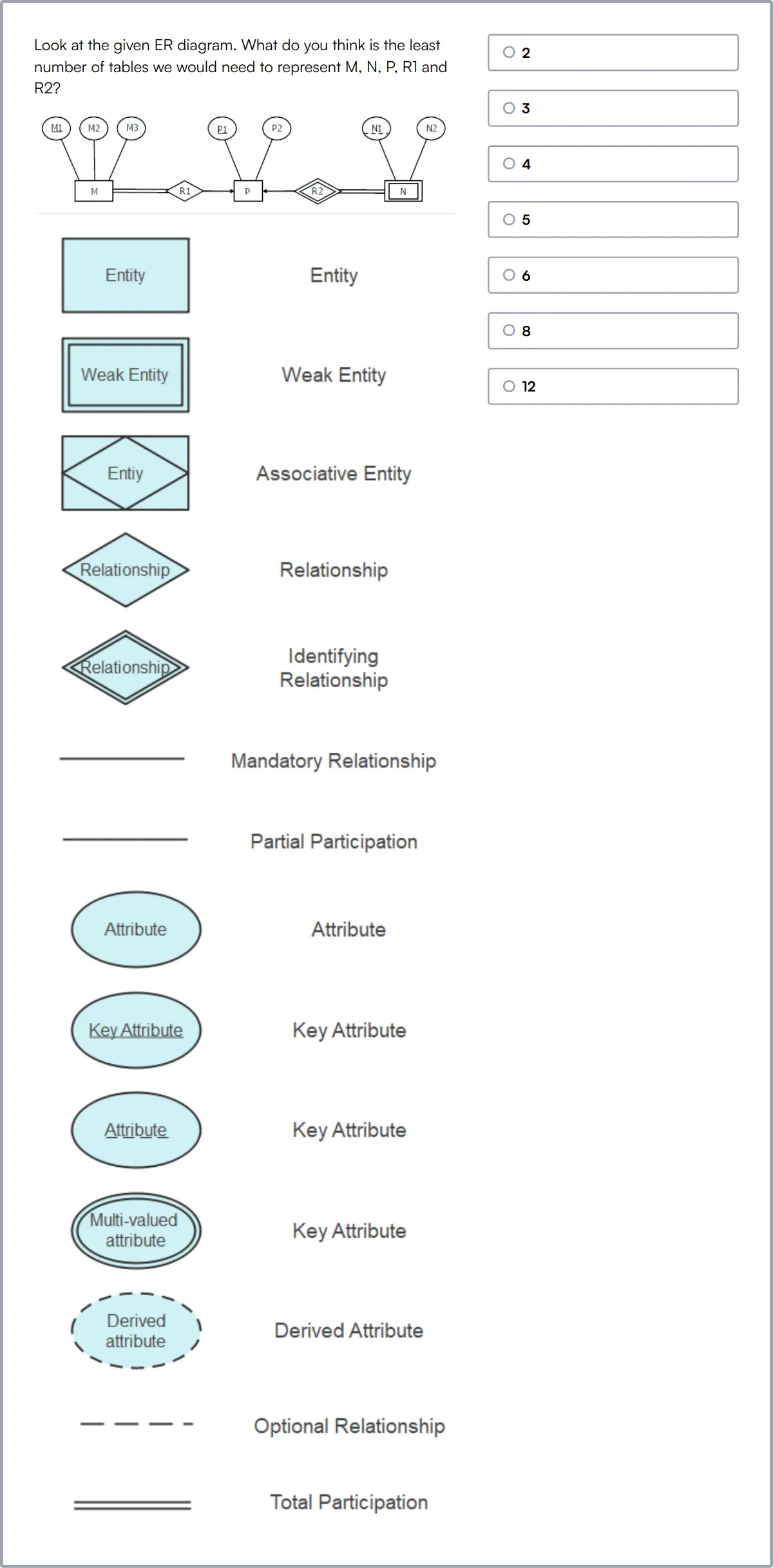
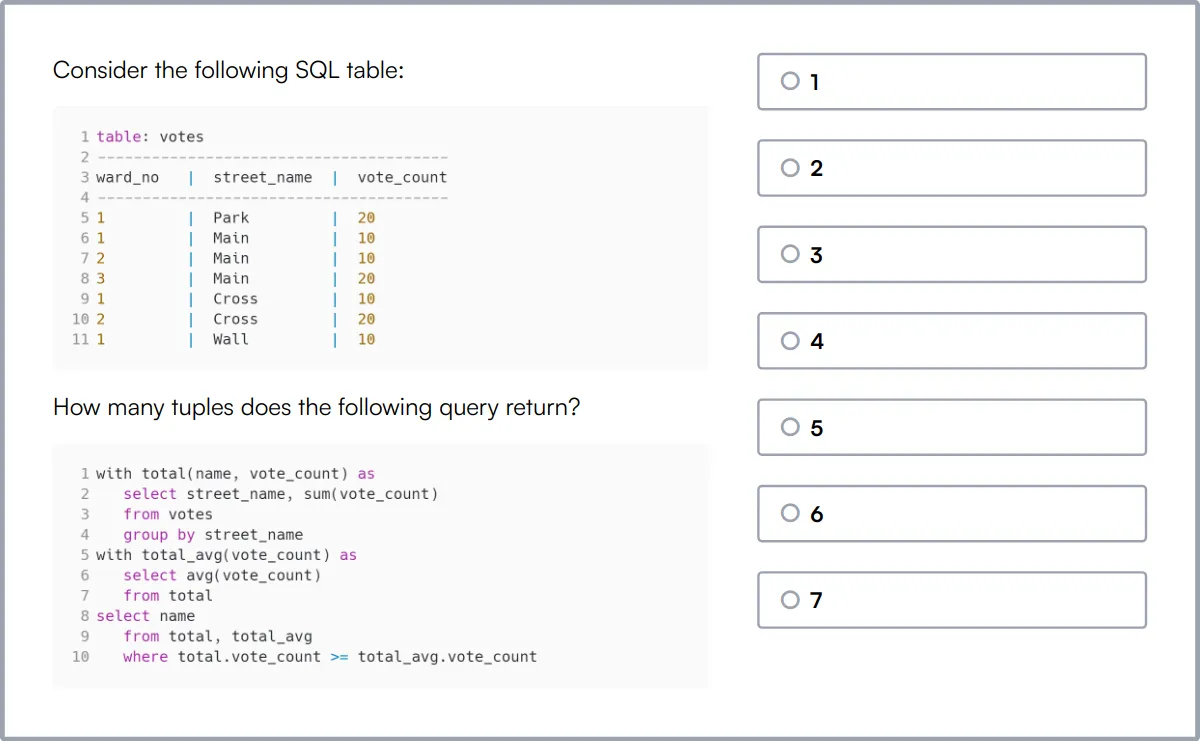
Test Online de SQL
Nuestro Test Online de SQL está diseñado para evaluar las habilidades de un candidato en la gestión de bases de datos SQL, desde las operaciones CRUD básicas hasta consultas complejas y la optimización de bases de datos.
La prueba desafía a los candidatos con escenarios que involucran la creación de bases de datos, la manipulación de tablas y funciones SQL avanzadas como joins, subconsultas y transacciones.
Los candidatos expertos demostrarán su capacidad para construir y administrar bases de datos eficientes y seguras, y realizar tareas sofisticadas de manipulación y recuperación de datos.
Resumen: Las 9 habilidades clave de un Ingeniero de Big Data y cómo evaluarlas
| Habilidad de Ingeniero de Big Data | Cómo evaluarlos |
|---|---|
| 1. Lenguajes de programación | Evaluar la competencia en lenguajes como Python, Java o Scala. |
| 2. Almacenamiento de datos | Evaluar la capacidad para diseñar y gestionar soluciones de almacenamiento de datos a gran escala. |
| 3. Procesos ETL | Verificar las habilidades en la extracción, transformación y carga de datos de manera eficiente. |
| 4. Ecosistema Hadoop | Medir la familiaridad con herramientas como HDFS, MapReduce y Hive. |
| 5. Modelado de datos | Determinar la capacidad para estructurar datos para un almacenamiento y recuperación óptimos. |
| 6. SQL y NoSQL | Medir qué tan bien un candidato consulta y gestiona la información en bases de datos. |
| 7. Seguridad de datos | Evaluar la comprensión de la protección de datos y las técnicas de encriptación. |
| 8. Plataformas en la nube | Evaluar la experiencia con los servicios de AWS, Azure o Google Cloud. |
| 9. Visualización de datos | Verificar la capacidad para crear representaciones visuales perspicaces de los datos. |
Prueba en línea de análisis de datos en Azure
30 minutos | 15 MCQs
La prueba de Análisis de datos en Azure evalúa el conocimiento y las habilidades de un candidato en la utilización de los servicios de Azure para tareas de análisis de datos. Cubre temas como la plataforma Azure, técnicas de análisis de datos, Power BI, SQL Server y almacén de datos.
[
Intente la prueba en línea de análisis de datos en Azure
](https://www.adaface.com/assessment-test/data-analytics-in-azure-test)
Preguntas frecuentes sobre las habilidades de un ingeniero de Big Data
¿Qué lenguajes de programación debería conocer un ingeniero de Big Data?
Los ingenieros de Big Data deben dominar lenguajes como Java, Python y Scala. Estos lenguajes se utilizan comúnmente para tareas de procesamiento y análisis de datos.
¿Cómo pueden los reclutadores evaluar el conocimiento de un candidato sobre el ecosistema Hadoop?
Los reclutadores pueden preguntar a los candidatos sobre su experiencia con componentes de Hadoop como HDFS, MapReduce, Hive y Pig. Las pruebas prácticas o las discusiones de proyectos también pueden ayudar a medir su experiencia.
¿Por qué el almacenamiento de datos es importante para los ingenieros de Big Data?
El almacenamiento de datos es importante porque permite el almacenamiento y la gestión de grandes volúmenes de datos. Ayuda a la consulta y el análisis eficientes, lo cual es crucial para la toma de decisiones basada en datos.
¿Cuál es el papel de los procesos ETL en la ingeniería de Big Data?
Los procesos ETL (Extract, Transform, Load - Extraer, Transformar, Cargar) se utilizan para recopilar datos de diversas fuentes, transformarlos en un formato utilizable y cargarlos en un almacén de datos u otros sistemas de almacenamiento.
¿Cómo se pueden evaluar las habilidades en SQL y NoSQL en un ingeniero de Big Data?
Las habilidades en SQL se pueden evaluar a través de consultas y tareas de diseño de bases de datos, mientras que las habilidades en NoSQL se pueden evaluar discutiendo la experiencia con bases de datos como MongoDB, Cassandra o Redis.
¿Con qué plataformas en la nube debería estar familiarizado un ingeniero de Big Data?
Los ingenieros de Big Data deben estar familiarizados con plataformas en la nube como AWS, Google Cloud y Azure. Estas plataformas ofrecen diversas herramientas y servicios para el procesamiento y almacenamiento de big data.
¿Qué tan importante es la seguridad de los datos para un ingeniero de Big Data?
La seguridad de los datos es fundamental para proteger la información confidencial. Los ingenieros de Big Data deben comprender el cifrado, los controles de acceso y los requisitos de cumplimiento para garantizar la integridad y privacidad de los datos.
¿Cuál es la importancia de la visualización de datos en la ingeniería de Big Data?
La visualización de datos ayuda a presentar información compleja sobre datos en un formato comprensible. Herramientas como Tableau, Power BI y D3.js se utilizan comúnmente para crear representaciones visuales de datos.
Next posts
- 70 preguntas de entrevista para consultores funcionales de SAP para hacer a los candidatos
- 46 preguntas de entrevista para consultores SAP FICO para hacer a los candidatos
- 79 Preguntas de entrevista para arquitectos de información para contratar a los mejores talentos
- 60 preguntas de entrevista para Gerentes de Éxito del Cliente para hacer a tus candidatos
- 67 preguntas de entrevista para especialistas en SEO para contratar al mejor talento