66 preguntas de entrevista sobre Azure Data Factory (y respuestas) para contratar a los mejores ingenieros de datos
Contratar a los expertos adecuados en Azure Data Factory es crucial para las organizaciones que buscan optimizar sus procesos de integración y transformación de datos. Como reclutador o gerente de contratación, tener una lista completa de preguntas de entrevista puede ayudarlo a evaluar eficazmente las habilidades y conocimientos de los candidatos en este servicio esencial de Azure.
Esta publicación de blog proporciona una colección seleccionada de preguntas de entrevista de Azure Data Factory, que van desde niveles básicos hasta avanzados. Hemos organizado las preguntas en categorías para ayudarlo a evaluar a los candidatos en diferentes niveles de experiencia y enfocarse en aspectos específicos de Azure Data Factory.
Al usar estas preguntas, estará mejor equipado para identificar a los mejores talentos para sus puestos de ingeniería de datos. Considere complementar su proceso de entrevista con una evaluación de habilidades de Azure previa a la selección para asegurarse de que está entrevistando a los candidatos más calificados.
Tabla de contenidos
10 preguntas y respuestas básicas de la entrevista de Azure Data Factory para evaluar a los candidatos
10 preguntas de la entrevista de Azure Data Factory para hacer a los ingenieros de datos junior
10 preguntas y respuestas intermedias de la entrevista de Azure Data Factory para hacer a los ingenieros de datos de nivel medio
15 preguntas avanzadas de la entrevista de Azure Data Factory para hacer a los ingenieros de datos senior
5 preguntas y respuestas de la entrevista de Azure Data Factory relacionadas con la integración de datos
9 preguntas y respuestas de la entrevista de Azure Data Factory relacionadas con las canalizaciones
7 preguntas situacionales de la entrevista de Azure Data Factory con respuestas para contratar a los mejores ingenieros de datos
¿Qué habilidades de Azure Data Factory debería evaluar durante la fase de la entrevista?
Contrate a los mejores talentos con pruebas de habilidades de Azure Data Factory y las preguntas de la entrevista correctas
Descargue la plantilla de preguntas de la entrevista de Azure Data Factory en múltiples formatos
10 preguntas y respuestas básicas de la entrevista de Azure Data Factory para evaluar a los candidatos

Para determinar si sus solicitantes tienen el conocimiento fundamental para trabajar eficazmente con Azure Data Factory, pregúnteles algunas de estas preguntas básicas de la entrevista. Esta lista le ayudará a evaluar su comprensión de los conceptos clave y los escenarios comunes, asegurando que contrate a la persona adecuada para su equipo.
1. ¿Cuáles son los componentes principales de Azure Data Factory?
Los componentes principales de Azure Data Factory incluyen Pipelines (tuberías), Activities (actividades), Datasets (conjuntos de datos), Linked Services (servicios vinculados) e Integration Runtimes (entornos de ejecución de integración). Las Pipelines son un grupo de actividades que realizan una unidad de trabajo. Las Activities representan un paso de procesamiento en una pipeline. Los Datasets contienen los datos en los que se está trabajando, los Linked Services son las cadenas de conexión y los Integration Runtimes proporcionan el entorno de cómputo.
Cuando los candidatos expliquen estos componentes, busque claridad y una sólida comprensión de cómo encaja cada pieza en el flujo de trabajo general de datos. Deben ser capaces de describir el propósito de cada componente y cómo interactúan entre sí para mover y transformar datos.
2. ¿Cómo maneja Azure Data Factory la transformación de datos?
Azure Data Factory maneja la transformación de datos mediante el uso de actividades de Data Flow (flujo de datos). Estas actividades permiten a los usuarios diseñar procesos de transformación de datos utilizando una interfaz gráfica sin escribir código. Las transformaciones comunes incluyen filtrar, ordenar, unir y agregar datos.
Los candidatos deben mostrar familiaridad con la interfaz gráfica y mencionar varias opciones de transformación disponibles. Busque una comprensión de cómo estas transformaciones se pueden aplicar en escenarios del mundo real y cómo ayudan a preparar los datos para su posterior análisis o almacenamiento.
3. ¿Puede explicar qué es un Linked Service en Azure Data Factory?
Un Linked Service en Azure Data Factory es similar a una cadena de conexión. Define la información de conexión necesaria para que Data Factory se conecte a recursos externos. Estos recursos pueden ser bases de datos, almacenamiento en la nube u otros servicios con los que Azure Data Factory interactúa.
Los candidatos deben articular la importancia de los Linked Services al establecer conexiones con orígenes y destinos de datos. Busque una comprensión de cómo configurarlos y administrar de forma segura las credenciales o claves.
4. ¿Qué es un Integration Runtime (IR) en Azure Data Factory?
Un Integration Runtime (IR) es la infraestructura informática utilizada por Azure Data Factory para proporcionar capacidades de integración de datos. Hay tres tipos: Azure IR, Self-hosted IR y Azure-SSIS IR. Cada tipo admite diferentes capacidades y escenarios, como el movimiento y la transformación de datos basados en la nube o la integración de datos locales.
Un candidato fuerte debe diferenciar entre los tipos de IR y explicar cuándo usar cada uno en función de los requisitos de integración. También deben mencionar consideraciones como la seguridad, el rendimiento y la escalabilidad.
5. ¿Cómo se supervisan y gestionan las ejecuciones de tuberías en Azure Data Factory?
La supervisión y gestión de las ejecuciones de tuberías en Azure Data Factory se pueden realizar a través del portal de Azure, donde se pueden ver las ejecuciones de tuberías, las ejecuciones de actividades y las ejecuciones de desencadenadores. También puede configurar alertas y notificaciones basadas en el éxito o el fracaso de la tubería.
Los candidatos deben mencionar el uso del panel de supervisión en el portal de Azure y, posiblemente, la integración de herramientas de registro y supervisión como Azure Monitor y Log Analytics. Busque su enfoque de supervisión proactiva y resolución de problemas.
6. ¿Cuáles son los beneficios de usar Azure Data Factory para los procesos ETL?
Azure Data Factory proporciona una plataforma escalable y flexible para los procesos ETL. Los beneficios incluyen la capacidad de manejar grandes volúmenes de datos, la integración con varias fuentes de datos, una amplia gama de conectores integrados y soporte para datos estructurados y no estructurados. Además, ofrece un modelo de precios de pago por uso.
El candidato ideal debe abordar la facilidad de uso, la flexibilidad y la escalabilidad de Azure Data Factory. También debe mencionar cómo simplifica la orquestación de flujos de trabajo de datos en comparación con las herramientas ETL tradicionales.
7. ¿Cómo garantiza Azure Data Factory la seguridad y el cumplimiento de los datos?
Azure Data Factory garantiza la seguridad y el cumplimiento de los datos a través de funciones como el cifrado de datos, la seguridad de la red y los controles de acceso. Los datos pueden ser encriptados tanto en reposo como en tránsito. La seguridad de la red se gestiona a través de Virtual Networks y Private Endpoints, y los controles de acceso se aplican utilizando Azure Active Directory.
Los candidatos deben enfatizar la importancia de estas características de seguridad y cómo se alinean con los requisitos de cumplimiento. Busque una comprensión de las mejores prácticas en seguridad de datos dentro del contexto de Azure Data Factory.
8. ¿Cuál es el papel de los desencadenadores en Azure Data Factory?
Los desencadenadores en Azure Data Factory se utilizan para invocar pipelines en función de ciertos eventos o programaciones. Hay diferentes tipos de desencadenadores, incluyendo Schedule, Tumbling Window y Event-based triggers, cada uno sirviendo para diferentes casos de uso, como la programación basada en el tiempo o la respuesta a la llegada de archivos de datos.
Una buena respuesta debería cubrir los diferentes tipos de disparadores (triggers) y cuándo usar cada uno. Los candidatos deberían demostrar una comprensión de cómo los disparadores ayudan a automatizar y gestionar los flujos de trabajo de datos de manera efectiva.
9. ¿Cómo implementa el manejo de errores en Azure Data Factory?
El manejo de errores en Azure Data Factory se puede implementar utilizando actividades como Try-Catch, configurando políticas de reintento y configurando alertas. Puede usar expresiones condicionales y registros personalizados para manejar y registrar errores de manera efectiva.
Los candidatos deberían discutir los diferentes mecanismos de manejo de errores y las mejores prácticas para implementar estrategias robustas de manejo de errores. Busque experiencia en el manejo de varios escenarios de fallos y en garantizar la integridad de los datos.
10. ¿Puede describir un escenario donde usó Azure Data Factory para resolver un problema complejo de flujo de trabajo de datos?
Al responder a esta pregunta, los candidatos deben describir un proyecto o escenario específico donde utilizaron Azure Data Factory para optimizar o resolver un problema de flujo de trabajo de datos. Deben esbozar el problema, los pasos que tomaron usando Azure Data Factory y el resultado. Se buscan explicaciones detalladas que muestren sus habilidades de resolución de problemas y experiencia práctica con Azure Data Factory. El candidato ideal debe resaltar su capacidad para diseñar e implementar flujos de trabajo de datos eficientes que cumplan con los objetivos del proyecto. 10 preguntas de entrevista de Azure Data Factory para hacer a ingenieros de datos junior ---------------------------------------------------------------------- 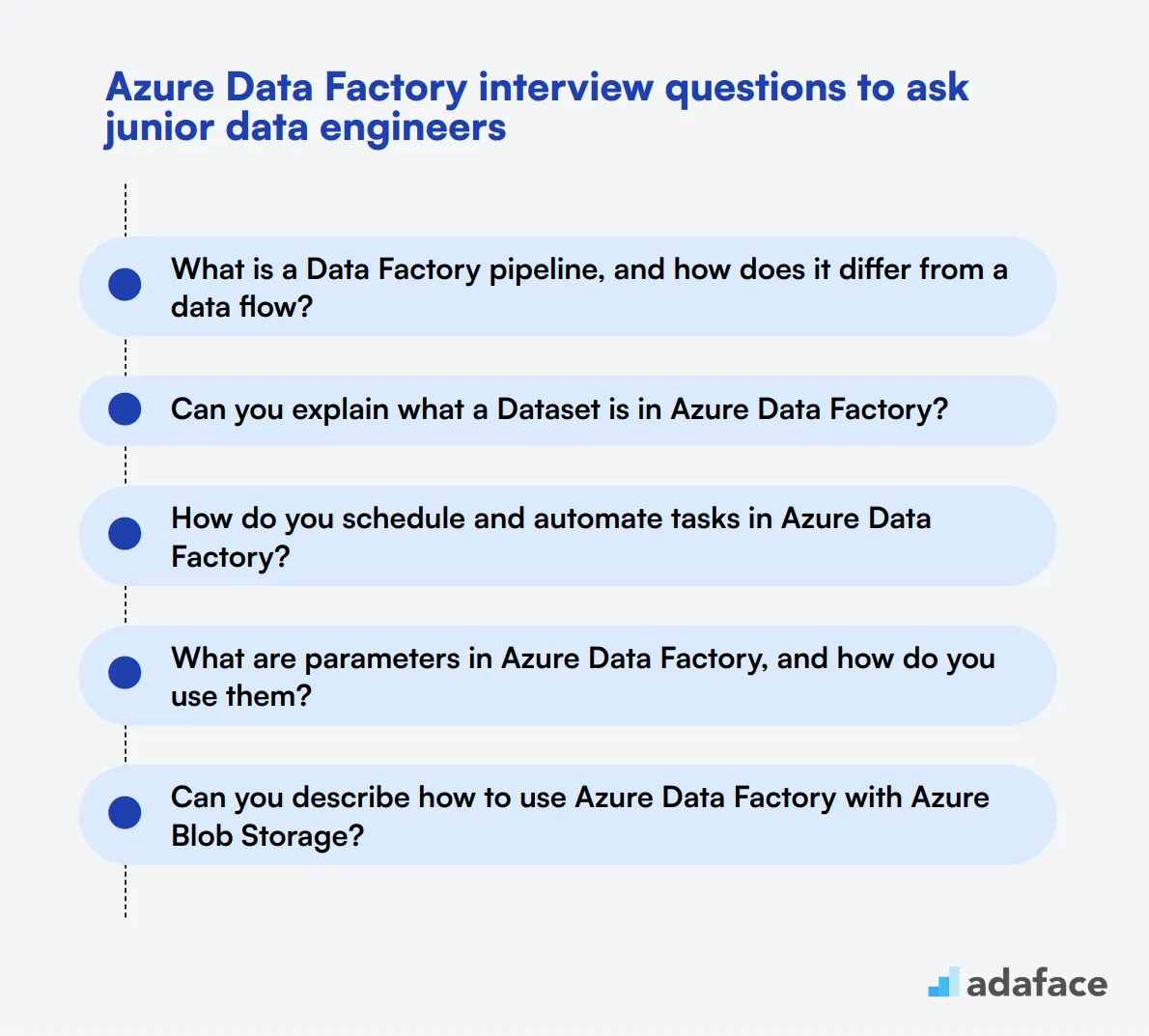 Para evaluar eficazmente las capacidades de los ingenieros de datos junior, considere usar esta lista de preguntas de entrevista de Azure Data Factory específicas. Estas preguntas pueden ayudarle a evaluar no solo sus conocimientos técnicos, sino también sus habilidades de resolución de problemas en escenarios del mundo real, asegurando que encuentre el ajuste adecuado para su equipo. Para obtener más información sobre qué buscar, consulte nuestra descripción del puesto de ingeniero de datos.
Para evaluar eficazmente las capacidades de los ingenieros de datos junior, considere usar esta lista de preguntas de entrevista de Azure Data Factory específicas. Estas preguntas pueden ayudarle a evaluar no solo sus conocimientos técnicos, sino también sus habilidades de resolución de problemas en escenarios del mundo real, asegurando que encuentre el ajuste adecuado para su equipo. Para obtener más información sobre qué buscar, consulte nuestra descripción del puesto de ingeniero de datos.
- ¿Qué es una canalización de Data Factory y en qué se diferencia de un flujo de datos? 2. ¿Puede explicar qué es un conjunto de datos (Dataset) en Azure Data Factory? 3. ¿Cómo se programan y automatizan tareas en Azure Data Factory? 4. ¿Qué son los parámetros en Azure Data Factory y cómo se usan? 5. ¿Puede describir cómo usar Azure Data Factory con Azure Blob Storage? 6. ¿Cuál es el propósito de la herramienta Copiar datos en Azure Data Factory? 7. ¿Cómo manejaría los cambios de esquema al migrar datos usando Azure Data Factory? 8. ¿Puede explicar el concepto de flujos de datos de mapeo en Azure Data Factory? 9. ¿Qué pasos tomaría para solucionar problemas de una canalización fallida en Azure Data Factory? 10. ¿Cómo integra Azure Data Factory con otros servicios de Azure, como Azure Functions?
10 preguntas y respuestas intermedias para entrevistas de Azure Data Factory para preguntar a ingenieros de datos de nivel medio

Para determinar si sus candidatos a ingenieros de datos de nivel medio tienen las habilidades para manejar tareas más complejas en Azure Data Factory, utilice estas preguntas de nivel intermedio. Están diseñadas para evaluar no solo el conocimiento técnico sino también la capacidad de pensar sobre la marcha y resolver problemas del mundo real.
1. ¿Cómo gestiona y organiza múltiples canalizaciones en Azure Data Factory?
La gestión y organización de múltiples canalizaciones en Azure Data Factory implica el uso de carpetas, etiquetas y convenciones de nomenclatura para mantener todo estructurado y fácil de navegar. Agrupar las canalizaciones relacionadas en carpetas puede ayudar a gestionarlas y mantenerlas.
Los candidatos también deben mencionar el uso de sistemas de control de versiones para realizar un seguimiento de los cambios y garantizar que las canalizaciones estén actualizadas. También podrían hablar sobre el aprovechamiento del panel de Azure Data Factory para monitorear el estado de todas las canalizaciones.
Busque candidatos que demuestren una estrategia clara de organización y mencionen técnicas como la modularización y la reutilización para mantener el proyecto mantenible.
2. ¿Puede explicar cómo optimiza el rendimiento de las canalizaciones en Azure Data Factory?
También podrían discutir el monitoreo y los diagnósticos para identificar cuellos de botella y optimizar la asignación de recursos. Ajustar la configuración del Entorno de Ejecución de Integración y escalar vertical o horizontalmente según la carga de trabajo es otro punto clave.
Una respuesta ideal incluirá ejemplos específicos y demostrará una comprensión de las estrategias de optimización del rendimiento tanto proactivas como reactivas.
3. ¿Qué pasos toma para garantizar la calidad de los datos en Azure Data Factory?
Garantizar la calidad de los datos en Azure Data Factory implica implementar actividades de validación y limpieza dentro de la canalización. Los candidatos deben mencionar el uso de perfiles de datos, reglas de validación de datos y mecanismos de manejo de errores para detectar y corregir problemas de datos de manera temprana.
También podrían discutir la importancia de la gestión de metadatos y el uso de herramientas o scripts externos para realizar comprobaciones de calidad de datos más avanzadas.
Los candidatos fuertes proporcionarán ejemplos específicos de cómo han garantizado la calidad de los datos en proyectos anteriores y discutirán la importancia del monitoreo y la mejora continuos.
4. ¿Cómo maneja los cambios en el esquema de datos de origen dentro de Azure Data Factory?
Manejar los cambios en el esquema de datos de origen en Azure Data Factory requiere una combinación de monitoreo, flexibilidad y automatización. Los candidatos deben mencionar el uso de las capacidades de deriva de esquema dentro de los flujos de datos de asignación para adaptarse a los cambios sin intervención manual.
También podrían hablar sobre la implementación del versionado de esquemas y el uso de mapeo dinámico para minimizar las interrupciones. Los scripts de automatización para detectar cambios en el esquema y actualizar las tuberías en consecuencia también pueden ser una parte clave de su estrategia.
Busque candidatos que demuestren un enfoque proactivo para manejar los cambios de esquema y que puedan proporcionar ejemplos de cómo lo han gestionado en proyectos anteriores.
5. ¿Cuál es su enfoque para integrar Azure Data Factory con fuentes de datos locales?
Integrar Azure Data Factory con fuentes de datos locales generalmente implica el uso de Self-hosted Integration Runtime, que actúa como un puente entre el servicio en la nube y las fuentes de datos locales. Los candidatos deben mencionar la configuración y ajuste de este entorno de ejecución para transferir datos de forma segura.
También podrían discutir consideraciones de red, como las reglas de firewall y las configuraciones de VPN, para garantizar un movimiento de datos seguro y confiable.
Un candidato ideal proporcionará ejemplos de integraciones exitosas y demostrará una comprensión de las implicaciones de seguridad y rendimiento involucradas.
6. ¿Cómo garantiza la transferencia segura de datos entre Azure Data Factory y otros servicios?
Garantizar la transferencia segura de datos entre Azure Data Factory y otros servicios implica el uso de cifrado tanto en reposo como en tránsito. Los candidatos deben mencionar el uso de HTTPS para el movimiento seguro de datos y el cifrado de datos dentro de Azure Storage utilizando Azure Key Vault.
También podrían discutir el control de acceso basado en roles (RBAC) y las identidades administradas para restringir el acceso y garantizar que solo los servicios autorizados puedan acceder a los datos.
Busque candidatos que prioricen la seguridad y proporcionen ejemplos específicos de cómo han implementado estas medidas en proyectos anteriores.
7. ¿Puede explicar cómo usa los parámetros en Azure Data Factory para hacer que sus canalizaciones sean dinámicas?
El uso de parámetros en Azure Data Factory permite la creación de canalizaciones dinámicas y reutilizables. Los candidatos deben mencionar la definición de parámetros a nivel de canalización y su uso para pasar diferentes valores, como nombres de archivos o conexiones a bases de datos, en tiempo de ejecución.
También podrían discutir cómo estos parámetros se pueden usar junto con variables y expresiones para controlar el flujo de la tubería y hacerla más flexible.
Un candidato ideal proporcionará ejemplos de cómo ha utilizado parámetros para simplificar sus flujos de trabajo y reducir la redundancia en sus tuberías.
8. ¿Cómo depura y soluciona problemas en Azure Data Factory?
La depuración y solución de problemas en Azure Data Factory implica el uso de las funciones integradas de supervisión y registro. Los candidatos deben mencionar la revisión del historial de ejecución de actividades, la comprobación de mensajes de error y el uso de los registros de diagnóstico para identificar y resolver problemas.
También podrían hablar sobre el uso del modo de depuración para probar actividades o tuberías individuales e implementar una gestión de errores sólida para detectar y gestionar excepciones.
Busque candidatos que demuestren un enfoque sistemático para la solución de problemas y puedan proporcionar ejemplos específicos de cómo han resuelto problemas complejos.
9. ¿Cómo maneja la ingestión de datos a gran escala en Azure Data Factory?
El manejo de la ingesta de datos a gran escala en Azure Data Factory implica el uso de técnicas eficientes de movimiento de datos y la optimización del rendimiento. Los candidatos deben mencionar el uso de herramientas como la Actividad de Copia de Azure Data Factory con paralelismo y particionamiento para acelerar la transferencia de datos.
También podrían discutir el uso de PolyBase o Azure Data Lake para manejar conjuntos de datos muy grandes y aprovechar la compresión de datos para reducir los tiempos de transferencia.
Los candidatos fuertes proporcionarán ejemplos de proyectos de ingesta de datos a gran escala que hayan gestionado y discutirán las estrategias que utilizaron para garantizar la escalabilidad y el rendimiento.
10. ¿Puede describir un escenario en el que optimizó un flujo de trabajo de datos en Azure Data Factory para un mejor rendimiento?
Optimizar un flujo de trabajo de datos en Azure Data Factory a menudo implica analizar el proceso existente e identificar los cuellos de botella. Los candidatos deben mencionar el uso de herramientas de monitoreo para identificar actividades lentas y luego aplicar optimizaciones como el procesamiento paralelo o la partición de datos.
También podrían hablar sobre la simplificación de transformaciones complejas, el uso de búsquedas en caché o el ajuste de la configuración de Integration Runtime para mejorar el rendimiento.
Un candidato ideal proporcionará un ejemplo detallado de un proyecto específico donde implementó estas optimizaciones y discutirá el impacto en el rendimiento y la eficiencia generales.
15 preguntas avanzadas de entrevista de Azure Data Factory para hacer a ingenieros de datos sénior

Para evaluar si los candidatos poseen las habilidades avanzadas necesarias para tareas complejas en Azure Data Factory, considere usar esta lista seleccionada de preguntas de entrevista. Estas preguntas pueden ayudarle a evaluar su experiencia y pericia en el manejo de flujos de trabajo de datos sofisticados, lo que las convierte en una herramienta útil para evaluar posibles contrataciones para roles como ingeniero de datos.
- ¿Puede explicar cómo implementa las prácticas de integración continua y despliegue continuo (CI/CD) en Azure Data Factory? 2. ¿Qué estrategias utiliza para optimizar el rendimiento de la integración de datos en Azure Data Factory? 3. ¿Cómo gestiona el control de versiones para sus pipelines y componentes de Data Factory? 4. ¿Puede describir una situación en la que tuvo que integrar Azure Data Factory con servicios de terceros? ¿Qué desafíos enfrentó? 5. ¿Cómo se asegura de que sus soluciones de Azure Data Factory sean escalables y puedan manejar cargas de trabajo incrementadas? 6. ¿Cuáles son algunas de las mejores prácticas para organizar y mantener archivos JSON utilizados en Azure Data Factory? 7. ¿Puede explicar cómo utiliza las dependencias de actividad de Azure Data Factory para gestionar flujos de trabajo complejos? 8. ¿Cómo gestiona el linaje de datos y el análisis de impacto en sus proyectos de Azure Data Factory? 9. ¿Qué métodos utiliza para mejorar la fiabilidad de las pipelines de datos y minimizar el tiempo de inactividad en Azure Data Factory? 10. ¿Puede hablar sobre su experiencia con el uso de Azure Data Factory para el procesamiento de datos en tiempo real? ¿Cuáles son las consideraciones clave? 11. ¿Cómo aborda la documentación para sus implementaciones de Azure Data Factory? 12. ¿Qué herramientas de monitoreo utiliza junto con Azure Data Factory y cómo mejoran la gestión de su flujo de trabajo? 13. ¿Puede explicar el uso de Actividades Personalizadas en Azure Data Factory y proporcionar un ejemplo de su aplicación? 14. ¿Cómo gestiona la gobernanza y el cumplimiento de datos dentro de sus flujos de trabajo de Azure Data Factory? 15. ¿Qué técnicas utiliza para gestionar y transformar grandes conjuntos de datos de manera eficiente en Azure Data Factory?
5 preguntas y respuestas de entrevista sobre Azure Data Factory relacionadas con la integración de datos

Para evaluar la comprensión de un candidato sobre la integración de datos utilizando Azure Data Factory, considere hacer estas preguntas perspicaces. Le ayudarán a evaluar el conocimiento práctico y las habilidades de resolución de problemas del solicitante en escenarios del mundo real. Recuerde, los mejores ingenieros de datos pueden explicar conceptos complejos de forma sencilla.
1. ¿Cómo abordaría la carga incremental de datos de un sistema de origen a un data warehouse utilizando Azure Data Factory?
Un candidato sólido debe esbozar una estrategia que incluya:
-
Identificar un indicador de cambio confiable (por ejemplo, marca de tiempo, número de versión)
-
Configurar un mecanismo de marca de agua para rastrear el último registro procesado
-
Crear una actividad de búsqueda para recuperar el último valor de la marca de agua
-
Configurar una actividad de copia con una consulta dinámica para obtener solo datos nuevos o modificados
-
Actualizar el valor de la marca de agua después de la copia de datos exitosa
Busque candidatos que enfaticen la importancia del manejo de errores y el registro en este proceso. También deben mencionar consideraciones para manejar eliminaciones en el sistema de origen y estrategias potenciales para escenarios de actualización completa.
2. ¿Puede explicar cómo implementaría dimensiones de cambio lento (SCD) Tipo 2 en Azure Data Factory?
Una respuesta ideal debe incluir los siguientes pasos:
-
Configurar un área de almacenamiento provisional para cargar los datos entrantes
-
Usar una actividad de búsqueda para comparar datos nuevos con datos de dimensión existentes
-
Implementar una división condicional para separar registros nuevos, actualizados y sin cambios
-
Para los registros actualizados, usar una actividad de actualización para establecer la fecha de finalización del registro activo actual
-
Usar una actividad de inserción para agregar registros nuevos y registros actualizados como nuevas versiones
-
Asegurar el manejo adecuado de las claves suplentes y los números de versión
Preste atención a los candidatos que discuten la importancia de mantener el linaje de datos y la precisión histórica. También deben mencionar consideraciones de rendimiento potenciales para dimensiones grandes y estrategias para optimizar el proceso.
3. ¿Cómo manejaría datos confidenciales al moverlos entre sistemas locales y Azure usando Data Factory?
Una respuesta completa debe cubrir múltiples aspectos de la seguridad de datos:
-
Uso de Azure Key Vault para almacenar y administrar de forma segura cadenas de conexión y credenciales confidenciales
-
Implementación de cifrado de datos en tránsito utilizando protocolos SSL/TLS
-
Utilización de la integración de Virtual Network (VNet) para una conectividad segura
-
Aplicación de cifrado a nivel de columna para datos altamente confidenciales
-
Implementación de técnicas de enmascaramiento de datos para entornos que no son de producción
Busque candidatos que enfaticen la importancia del cumplimiento de las regulaciones de protección de datos como GDPR o HIPAA. También deben mencionar la necesidad de auditorías de seguridad periódicas y el principio de mínimo privilegio al configurar el acceso a los datos.
4. Describa cómo implementaría un patrón de fan-out/fan-in para el procesamiento paralelo en Azure Data Factory.
Una respuesta sólida debe describir los siguientes pasos:
-
Use una actividad Obtener metadatos para recuperar una lista de archivos o particiones de datos
-
Implemente una actividad ForEach para iterar sobre la lista
-
Dentro de ForEach, use la ejecución paralela para procesar múltiples elementos simultáneamente
-
Configure pipelines o actividades individuales para cada tarea de procesamiento
-
Use una actividad Esperar para asegurar que todas las ejecuciones paralelas se completen
-
Implemente una actividad final para consolidar o procesar más los resultados
Evalúe a los candidatos que discutan consideraciones como las limitaciones de recursos, el manejo de errores en ejecuciones paralelas y estrategias para monitorear y registrar tareas paralelas. También deben mencionar el uso potencial de desencadenadores de ventana de desplazamiento (tumbling window) para escenarios recurrentes de fan-out/fan-in.
5. ¿Cómo abordaría la prueba y validación de tuberías de datos en Azure Data Factory?
Una respuesta ideal debe cubrir múltiples estrategias de prueba:
-
Pruebas unitarias de actividades individuales y segmentos de tubería pequeños
-
Pruebas de integración de tuberías completas con conjuntos de datos de muestra
-
Pruebas de rendimiento para asegurar que las tuberías cumplan con los acuerdos de nivel de servicio (SLA) y escalen apropiadamente
-
Pruebas de calidad de datos para verificar la integridad y precisión de los datos procesados
-
Pruebas de regresión al realizar cambios en las tuberías existentes
Busque candidatos que enfaticen la importancia de las pruebas automatizadas y las prácticas de integración continua/implementación continua (CI/CD). También deben mencionar el uso de las capacidades de depuración de Azure Data Factory y la posible integración con Azure DevOps para flujos de trabajo de prueba completos.
9 preguntas y respuestas de entrevista de Azure Data Factory relacionadas con las tuberías

Para determinar si sus solicitantes tienen las habilidades adecuadas para administrar y optimizar tuberías en Azure Data Factory, pregúnteles algunas de estas preguntas esenciales de entrevista relacionadas con las tuberías. Estas preguntas están diseñadas para evaluar su comprensión práctica y sus habilidades para resolver problemas, asegurando que encuentre la mejor opción para su equipo.
1. ¿Cómo diseña una canalización eficiente en Azure Data Factory?
Diseñar una canalización eficiente en Azure Data Factory implica comprender el flujo de datos y los requisitos específicos de la tarea. Los candidatos deben mencionar la importancia de dividir el flujo de trabajo en actividades manejables, usar el procesamiento en paralelo cuando sea posible y optimizar el movimiento de datos para minimizar la latencia.
Una respuesta ideal demostrará una clara comprensión del ajuste del rendimiento, el uso de desencadenadores y programaciones, y la importancia del monitoreo y el registro para asegurar que la canalización se ejecute sin problemas. Busque candidatos que puedan articular ejemplos específicos de su experiencia pasada.
2. ¿Qué estrategias utiliza para manejar grandes volúmenes de datos en las canalizaciones de Azure Data Factory?
Manejar grandes volúmenes de datos requiere una combinación de partición de datos, uso de procesamiento en paralelo y optimización del movimiento de datos. Los candidatos deben discutir técnicas como la segmentación de conjuntos de datos grandes, la utilización de la función PolyBase para una carga de datos eficiente y el aprovechamiento de los recursos escalables de Azure para manejar picos de carga.
Los candidatos fuertes también mencionarán el monitoreo y el ajuste de las métricas de rendimiento, así como la implementación de mecanismos de reintento y manejo de errores para garantizar la integridad de los datos. Busque ejemplos detallados de cómo han gestionado el procesamiento de datos a gran escala en sus roles anteriores.
3. ¿Cómo soluciona los problemas de rendimiento en una canalización de Azure Data Factory?
La solución de problemas de rendimiento implica varios pasos, incluyendo la revisión de los registros de actividad de la canalización, el monitoreo de la utilización de recursos y la identificación de cuellos de botella en el movimiento o transformación de datos. Los candidatos deben mencionar herramientas como Azure Monitor y Log Analytics para obtener información detallada.
Una respuesta efectiva incluirá estrategias específicas para aislar problemas, como probar componentes individuales, ajustar la configuración de paralelismo u optimizar las configuraciones de la fuente de datos. Los reclutadores deben buscar candidatos que demuestren un enfoque metódico para la resolución de problemas y experiencia con escenarios reales de solución de problemas.
4. ¿Cuáles son algunas de las mejores prácticas para administrar las dependencias entre actividades en una canalización de Data Factory?
La gestión de dependencias implica el uso de las funciones integradas de Azure Data Factory, como las dependencias de actividad, para controlar la secuencia de operaciones. Los candidatos deben discutir el uso de condiciones de éxito, fallo y finalización para manejar varias rutas de ejecución.
Busque respuestas que incluyan ejemplos de flujos de trabajo complejos que hayan gestionado, así como la forma en que garantizan la consistencia de los datos y manejan los errores. Un candidato ideal también mencionará la importancia de documentar las dependencias y mantener configuraciones de pipeline claras para el mantenimiento y escalabilidad futuros.
5. ¿Puede explicar el concepto de un punto de control (checkpoint) en un pipeline y su importancia?
Un punto de control de pipeline es un mecanismo para guardar el estado de una ejecución de pipeline en ciertos puntos. Esto es especialmente útil para pipelines de larga duración, ya que permite que el proceso se reanude desde el último punto de control en caso de fallo, en lugar de comenzar desde el principio.
Los candidatos deben explicar cómo los puntos de control ayudan a mejorar la fiabilidad y la eficiencia de los flujos de trabajo de procesamiento de datos. Deben proporcionar ejemplos de escenarios en los que han implementado puntos de control y discutir los beneficios observados. Una respuesta ideal destacará su comprensión de la tolerancia a fallos y la consistencia de los datos.
6. ¿Cómo gestiona la evolución del esquema en los pipelines de Azure Data Factory?
La gestión de la evolución del esquema implica estrategias como el uso de las capacidades de desviación del esquema en los flujos de datos de asignación, el aprovechamiento de formatos de datos flexibles como JSON y el mantenimiento de un registro de esquema versionado. Los candidatos deben discutir cómo gestionan los cambios en la estructura de los datos sin interrumpir las operaciones del pipeline.
Una respuesta sólida incluirá ejemplos de herramientas y prácticas utilizadas para detectar y adaptarse a los cambios de esquema, como comprobaciones de validación de datos y notificaciones automatizadas. Busque candidatos que demuestren un enfoque proactivo para mantener la integridad de los datos y minimizar el tiempo de inactividad durante las actualizaciones del esquema.
7. ¿Qué métodos utiliza para garantizar la calidad de los datos en sus pipelines?
Garantizar la calidad de los datos implica implementar pasos de validación, actividades de limpieza de datos y monitorear la integridad de los datos a lo largo de la pipeline. Los candidatos deben mencionar técnicas como el perfilado de datos, el uso de actividades personalizadas para validaciones complejas y el mantenimiento de registros de auditoría detallados.
Busque respuestas que incluyan ejemplos específicos de problemas de calidad de datos que hayan encontrado y cómo los abordaron. Los candidatos fuertes también discutirán la importancia del monitoreo continuo y el uso de métricas para mantener altos estándares de calidad de datos.
8. ¿Cómo administra y controla la versión de las pipelines de Azure Data Factory?
La gestión y el control de versiones implican el uso de sistemas de control de código fuente como Git integrado con Azure Data Factory. Los candidatos deben discutir cómo organizan su repositorio, siguen estrategias de ramificación e implementan pipelines de CI/CD para automatizar las implementaciones.
Las respuestas ideales incluirán ejemplos de sus prácticas de control de versiones, cómo manejan múltiples entornos (desarrollo, staging, producción) y su enfoque de estrategias de reversión. Busque candidatos que enfaticen la importancia del desarrollo colaborativo y el mantenimiento de un historial claro de cambios.
9. ¿Cómo optimiza el costo de ejecución de las canalizaciones de Azure Data Factory?
Optimizar el costo implica varias estrategias, como programar las canalizaciones para que se ejecuten durante las horas de menor actividad, minimizar el movimiento de datos y utilizar opciones de almacenamiento rentables. Los candidatos también deben discutir la importancia de monitorear el uso de recursos y ajustar las actividades para garantizar una ejecución eficiente.
Una respuesta sólida incluirá ejemplos de medidas de ahorro de costos que hayan implementado, así como su enfoque para equilibrar el rendimiento y el costo. Busque candidatos que demuestren una comprensión profunda del modelo de precios de Azure y cómo aprovecharlo para optimizar los gastos.
7 preguntas de entrevista situacionales de Azure Data Factory con respuestas para contratar a los mejores ingenieros de datos

¿Listo para sumergirte en el mundo de Azure Data Factory con tus candidatos? Estas preguntas situacionales te ayudarán a evaluar el conocimiento práctico y las habilidades de resolución de problemas de un ingeniero de datos. Úsalas para descubrir cómo los candidatos aplican su experiencia en Azure Data Factory en escenarios del mundo real.
1. ¿Cómo diseñaría una tubería de datos en Azure Data Factory para manejar cargas incrementales diarias desde múltiples sistemas de origen?
Un candidato fuerte debe esbozar una estrategia que incluya:
-
Usar actividades de búsqueda (lookup) para identificar la última marca de tiempo procesada
-
Implementar filtros en la consulta de origen para extraer solo datos nuevos o modificados
-
Utilizar actividades de copia con los tipos de destino apropiados para cada destino
-
Implementar mecanismos de manejo de errores y registro (logging)
-
Configurar disparadores (triggers) apropiados para la ejecución diaria
Busque candidatos que enfaticen la importancia de los enfoques basados en metadatos y la parametrización para que la tubería sea flexible y reutilizable en múltiples sistemas de origen. También deben mencionar consideraciones para manejar posibles cambios en los sistemas de origen o tiempo de inactividad.
2. Describa una situación en la que tuvo que optimizar el rendimiento de un proceso de integración de datos a gran escala en Azure Data Factory. ¿Qué pasos tomó?
Una respuesta ideal debe incluir:
-
Analizar la estructura actual de la tubería e identificar cuellos de botella
-
Implementar el procesamiento paralelo donde sea posible
-
Optimizar las actividades de movimiento de datos (por ejemplo, usando PolyBase para transferencias de datos grandes a Azure Synapse)
-
Aprovechando los tipos de Integration Runtime adecuados según la ubicación de los datos
-
Ajustando la configuración de la actividad de copia, como el grado de paralelismo de la copia
-
Implementando estrategias de partición de datos
Preste atención a los candidatos que mencionen las herramientas de monitoreo que utilizaron para identificar problemas de rendimiento y cómo midieron las mejoras. Los candidatos fuertes también podrían discutir las compensaciones entre rendimiento y costo, mostrando una comprensión holística de los principios de ingeniería en la nube.
3. ¿Cómo implementaría una verificación de la calidad de los datos dentro de una canalización de Azure Data Factory?
Una respuesta completa debe cubrir:
-
Uso de transformaciones de flujo de datos o scripts SQL para realizar la validación de datos
-
Implementación de divisiones condicionales para separar registros válidos e inválidos
-
Utilización de las reglas de calidad de datos integradas de Azure Data Factory en flujos de datos de mapeo
-
Registro y almacenamiento de métricas de calidad de datos para el análisis de tendencias
-
Configuración de alertas para cuando se superan los umbrales de calidad de datos
Busque candidatos que enfaticen la importancia de definir reglas y umbrales claros de calidad de datos. También deben mencionar cómo manejarían los datos no válidos, ya sea mediante rechazo, cuarentena o procesos de corrección automatizados. Los candidatos fuertes podrían discutir la integración de estas comprobaciones con iniciativas más amplias de gobierno de datos.
4. ¿Puede explicar cómo implementaría una dimensión de cambio lento (SCD) Tipo 2 en Azure Data Factory?
Una respuesta sólida debe incluir los siguientes pasos:
-
Usar una actividad de búsqueda para verificar la existencia de registros en la tabla de dimensiones
-
Implementar una división condicional en un flujo de datos de mapeo para separar registros nuevos, actualizados y sin cambios
-
Para los registros actualizados: Establecer la fecha de finalización del registro actual e insertar un nuevo registro con la información actualizada
-
Para registros nuevos: Insertarlos con la fecha actual como fecha de inicio
-
Asegurarse de que la clave suplente se gestione y se incremente correctamente para los nuevos registros
Busque candidatos que mencionen la importancia de manejar valores NULL y garantizar la consistencia de los datos. También deben discutir consideraciones para la optimización del rendimiento al tratar con tablas de dimensiones grandes. Los candidatos fuertes podrían mencionar enfoques alternativos, como el uso de sentencias merge en SQL para un mejor rendimiento en ciertos escenarios.
5. ¿Cómo abordaría la migración de un paquete SSIS local a Azure Data Factory?
Una respuesta completa debe cubrir los siguientes puntos:
-
Evaluar el paquete SSIS existente para determinar la compatibilidad con Azure
-
Utilizando el entorno de ejecución de integración SSIS en Azure Data Factory
-
Usando el entorno de ejecución de integración Azure-SSIS para escenarios de "lift-and-shift"
-
Refactorizando transformaciones complejas en flujos de datos de asignación de Azure Data Factory
-
Implementando Azure Key Vault para la gestión segura de credenciales
-
Configurando conexiones híbridas para acceder a fuentes de datos locales
Busque candidatos que enfaticen la importancia de las pruebas y la validación exhaustivas durante todo el proceso de migración. También deben discutir estrategias para manejar las diferencias en las características de rendimiento entre los entornos locales y en la nube. Los candidatos fuertes podrían mencionar herramientas o scripts que hayan utilizado para automatizar partes del proceso de migración.
6. Describa cómo implementaría el manejo de errores y el registro en una canalización de Azure Data Factory.
Una respuesta efectiva debe incluir:
-
Usar actividades try-catch para manejar errores a nivel de actividad
-
Implementar actividades de registro personalizadas para registrar información detallada sobre errores
-
Utilizar Azure Monitor y Log Analytics para el registro centralizado
-
Configurar reglas de alerta para errores críticos
-
Implementar lógica de reintento para errores transitorios
-
Usar parámetros de canalización para controlar el comportamiento de manejo de errores
Busque candidatos que enfaticen la importancia de crear mensajes de error significativos y accionables. También deben discutir estrategias para manejar diferentes tipos de errores (por ejemplo, errores de datos vs. errores del sistema) y cómo utilizarían los datos de registro para mejorar la fiabilidad de la tubería a lo largo del tiempo. Los candidatos fuertes podrían mencionar cómo integran el manejo de errores con sistemas más amplios de monitoreo y alerta.
7. ¿Cómo diseñaría una solución en Azure Data Factory para manejar archivos que llegan a intervalos irregulares?
Una respuesta completa debe incluir:
-
Implementación de un desencadenador de ventana de desplazamiento con un intervalo corto
-
Uso de las actividades Obtener metadatos y Filtrar para buscar nuevos archivos
-
Implementación de una actividad ForEach para procesar múltiples archivos si están presentes
-
Utilización de Azure Functions para una lógica de detección de archivos más compleja si es necesario
-
Implementación de registros y monitoreo apropiados para rastrear el procesamiento de archivos
Busque candidatos que discutan estrategias para manejar tamaños de archivo variables y posibles retrasos en el procesamiento. También deben mencionar consideraciones para el manejo y la recuperación de errores en caso de fallas. Los candidatos fuertes podrían discutir cómo optimizarían la solución para la rentabilidad, especialmente en escenarios con largos períodos de inactividad.
¿Qué habilidades de Azure Data Factory debe evaluar durante la fase de entrevista?
En una sola entrevista, es poco probable cubrir todos los aspectos de las capacidades de un candidato. Sin embargo, para los roles de Azure Data Factory, centrarse en algunas habilidades clave puede evaluar eficazmente su competencia y adecuación para el puesto.

Integración de Datos
La integración de datos es crucial en Azure Data Factory, ya que combina datos de múltiples fuentes en una única vista unificada. Esta habilidad es esencial para garantizar que diferentes tipos de datos puedan comunicarse y trabajar juntos sin problemas.
Para evaluar esta habilidad, considera usar una prueba de evaluación que incluya preguntas de opción múltiple relacionadas con la integración de datos. Quizás quieras revisar nuestra prueba en línea de Azure Data Factory para preguntas relevantes.
Adicionalmente, puedes hacer preguntas de entrevista específicas para evaluar las habilidades de integración de datos de un candidato.
¿Puedes explicar cómo configurarías una tubería en Azure Data Factory para integrar datos de varias fuentes locales y en la nube?
Busque candidatos que puedan describir claramente los pasos, las herramientas y las metodologías involucradas en la configuración de dicha tubería. Deben demostrar una comprensión tanto de la integración local como en la nube.
Flujos de trabajo ETL
Los flujos de trabajo de Extracción, Transformación, Carga (ETL) son un componente central de Azure Data Factory. Estos flujos de trabajo permiten el movimiento y la transformación de datos de un lugar a otro, haciéndolos accesibles y utilizables en diferentes sistemas.
Puede evaluar esta habilidad utilizando una prueba de evaluación que presenta preguntas de opción múltiple relevantes. Nuestra prueba en línea de Azure Data Factory incluye preguntas sobre los flujos de trabajo ETL.
También puede hacer preguntas específicas durante la entrevista para evaluar su experiencia con los flujos de trabajo ETL.
Describa un flujo de trabajo ETL complejo que haya implementado en Azure Data Factory y los desafíos que enfrentó.
Concéntrese en cómo los candidatos abordan los desafíos, su enfoque para la resolución de problemas y su comprensión de los procesos ETL. Los ejemplos prácticos y los desafíos específicos superados pueden ser grandes indicadores.
Transformación de datos
La transformación de datos es necesaria para convertir los datos en un formato utilizable. En Azure Data Factory, esto implica la limpieza de datos, la clasificación, la agregación y la modificación para satisfacer las necesidades del negocio.
Considere usar nuestra prueba en línea de Azure Data Factory, que incluye preguntas para evaluar las habilidades de transformación de datos de un candidato.
Haga preguntas que aborden específicamente su comprensión y experiencia con la transformación de datos.
¿Cómo usa Azure Data Factory para transformar datos sin procesar en un formato adecuado para las herramientas de inteligencia empresarial?
Escuche explicaciones detalladas del proceso de transformación, incluidas las herramientas y funciones utilizadas dentro de Azure Data Factory. La capacidad de articular escenarios de la vida real y los pasos dados indicará su competencia.
Contrata a los mejores talentos con pruebas de habilidades de Azure Data Factory y las preguntas de entrevista adecuadas.
Al contratar para roles que requieren habilidades de Azure Data Factory, es importante confirmar que los candidatos poseen la experiencia necesaria. Evaluar estas habilidades con precisión asegura que encuentres la persona adecuada para tu equipo.
Una forma efectiva de evaluar estas habilidades es utilizando pruebas de habilidades específicas. Considera revisar nuestra prueba de Azure Data Factory para medir las capacidades de los candidatos de manera efectiva.
Después de implementar esta prueba, podrás preseleccionar a los mejores solicitantes según su desempeño. Esto te permite enfocar tus esfuerzos de entrevista en los candidatos que realmente cumplen con tus requisitos.
Para dar el siguiente paso en tu proceso de contratación, visita nuestra biblioteca de pruebas de evaluación para explorar pruebas adicionales y registrarte en nuestra plataforma. Equipa tu proceso de contratación con las herramientas adecuadas para el éxito.
Prueba en línea de Microsoft Azure
25 minutos | 12 preguntas de opción múltiple (MCQ)
La prueba en línea de Azure evalúa la capacidad de un candidato para crear y escalar máquinas virtuales, opciones de almacenamiento y redes virtuales con Azure. La prueba utiliza preguntas MCQ basadas en escenarios para evaluar la comprensión de Azure Compute (máquinas virtuales, servicios de aplicaciones, funciones), Azure Storage (SQL, Blob, SQL), Azure Networking (redes virtuales, puerta de enlace, NSG) y seguridad de Azure.
Prueba el Examen en Línea de Microsoft Azure
Descarga la plantilla de preguntas para la entrevista de Azure Data Factory en múltiples formatos

Preguntas frecuentes sobre la entrevista de Azure Data Factory
Azure Data Factory es un servicio de integración de datos que te permite crear, programar y orquestar pipelines de datos.
Te permite extraer datos de diversas fuentes, transformarlos según sea necesario y cargarlos en soluciones de almacenamiento de datos.
Evalúa su comprensión de la integración de datos, los flujos de trabajo ETL y la experiencia específica con las herramientas y características de Azure Data Factory.
Concéntrate en conceptos básicos, experiencia práctica y su capacidad para aplicar conocimientos fundamentales para resolver problemas.
Los ingenieros senior suelen tener conocimientos avanzados, experiencia con flujos de trabajo de datos complejos y la capacidad de optimizar y solucionar problemas de manera efectiva.
Los desafíos comunes incluyen el manejo de grandes conjuntos de datos, la optimización del rendimiento de los pipelines y la garantía de la seguridad y el cumplimiento de los datos.
Next posts
- 70 preguntas de entrevista para consultores funcionales de SAP para hacer a los candidatos
- 46 preguntas de entrevista para consultores SAP FICO para hacer a los candidatos
- 79 Preguntas de entrevista para arquitectos de información para contratar a los mejores talentos
- 60 preguntas de entrevista para Gerentes de Éxito del Cliente para hacer a tus candidatos
- 67 preguntas de entrevista para especialistas en SEO para contratar al mejor talento