Test Duration
45 mínimos
Difficulty Level
Moderate
Questions
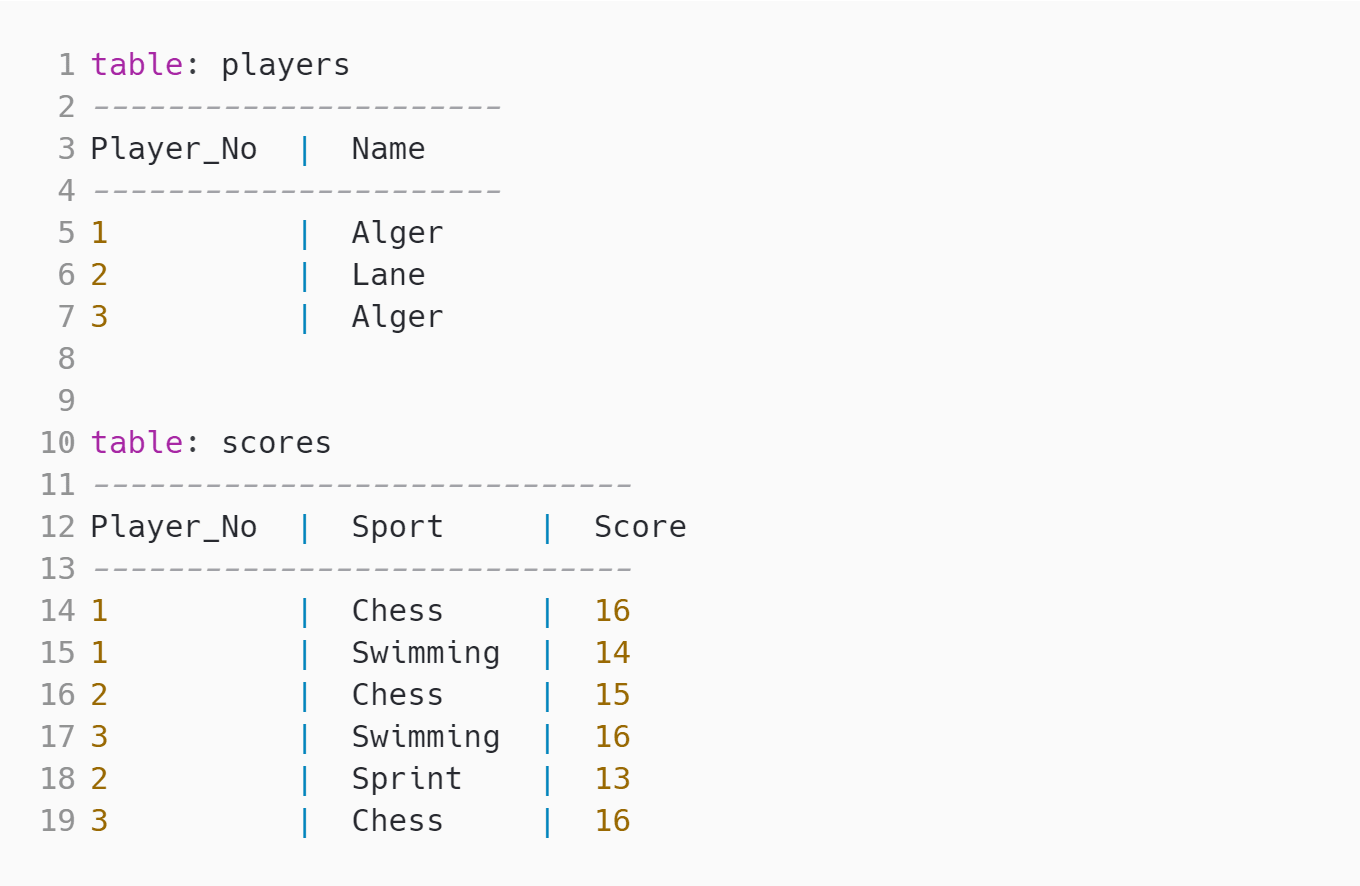
- 7 ETL MCQs
- 4 Sql MCQs
- 3 Data Warehouse MCQs
- 3 Data Modeling MCQs
Availability
Ready to use
About the test:
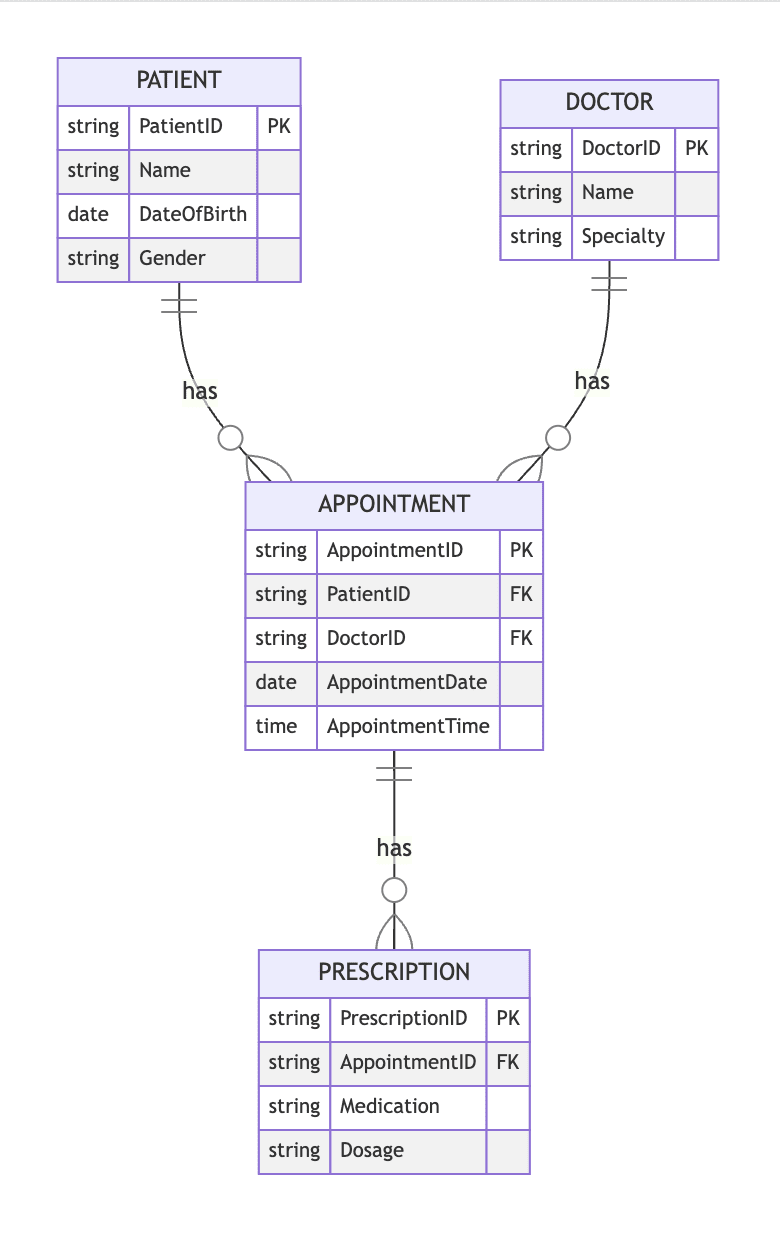
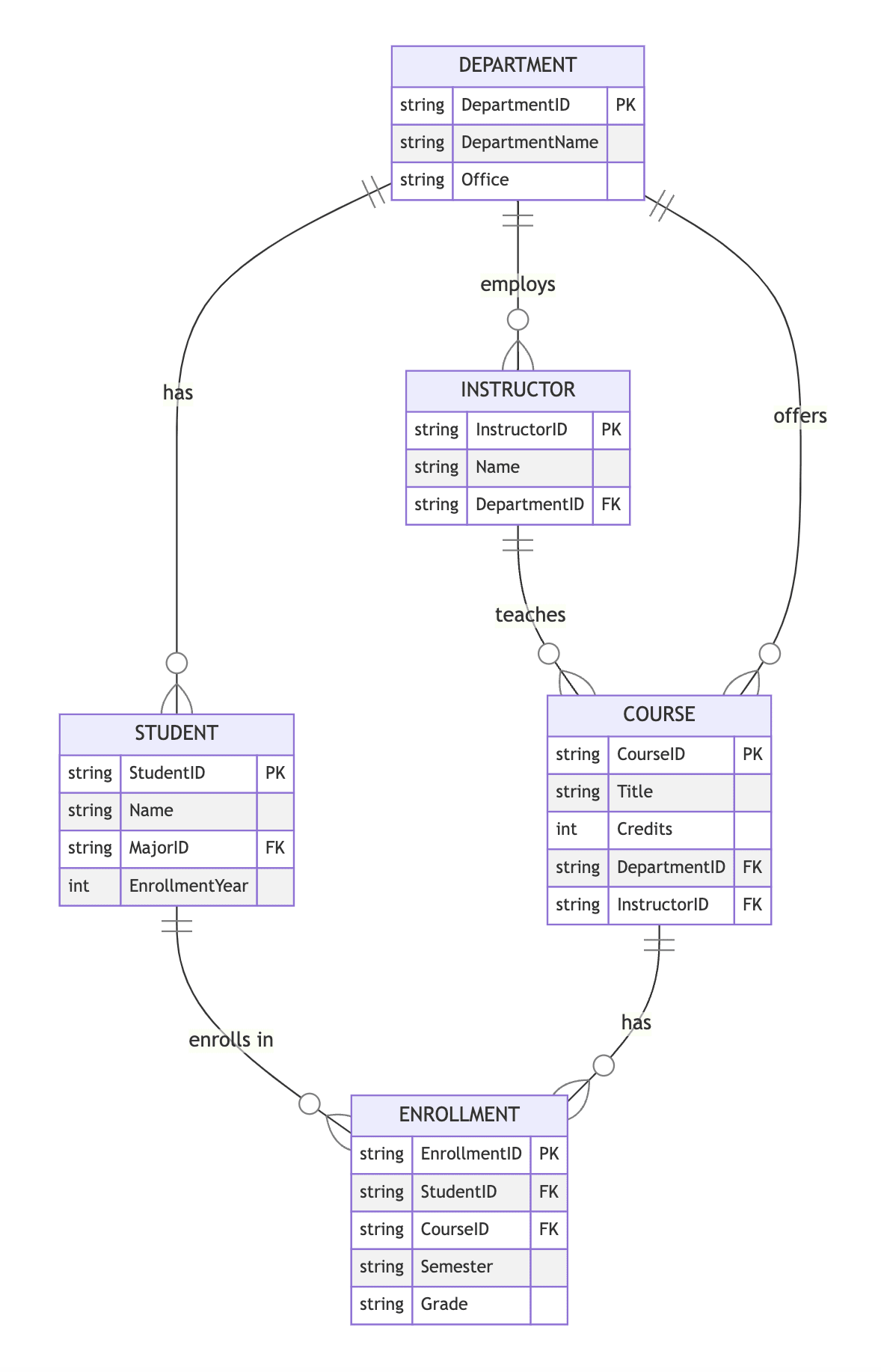
La evaluación ETL La prueba evalúa la capacidad de un candidato para identificar las herramientas utilizadas para extraer los datos, fusionar datos extraídos de manera lógica o física, definir las transformaciones para aplicar a los datos de origen para que los datos contextuales y los métodos de intercambio para cargar datos en el sistema de destino.
Covered skills:
Test Duration
45 mínimos
Difficulty Level
Moderate
Questions
Availability
Ready to use
The ETL Assessment Test helps recruiters and hiring managers identify qualified candidates from a pool of resumes, and helps in taking objective hiring decisions. It reduces the administrative overhead of interviewing too many candidates and saves time by filtering out unqualified candidates at the first step of the hiring process.
The test screens for the following skills that hiring managers look for in candidates:
Traditional assessment tools use trick questions and puzzles for the screening, which creates a lot of frustration among candidates about having to go through irrelevant screening assessments.
The main reason we started Adaface is that traditional pre-employment assessment platforms are not a fair way for companies to evaluate candidates. At Adaface, our mission is to help companies find great candidates by assessing on-the-job skills required for a role.
Why we started AdafaceWe have a very high focus on the quality of questions that test for on-the-job skills. Every question is non-googleable and we have a very high bar for the level of subject matter experts we onboard to create these questions. We have crawlers to check if any of the questions are leaked online. If/ when a question gets leaked, we get an alert. We change the question for you & let you know.
How we design questionsEstas son solo una pequeña muestra de nuestra biblioteca de más de 10,000 preguntas. Las preguntas reales sobre esto Prueba de evaluación ETL no se puede obtener.
| 🧐 Question | |||||
|---|---|---|---|---|---|
Medium Data Merging | Solve | ||||
Medium Data Updates | Solve | ||||
Medium SQL in ETL Process | Solve | ||||
Medium Trade Index | Solve | ||||
Medium Multi Select | Solve | ||||
Medium nth highest sales | Solve | ||||
Medium Select & IN | Solve | ||||
Medium Sorting Ubers | Solve | ||||
Hard With, AVG & SUM | Solve | ||||
Medium Marketing Database | Solve | ||||
Medium Multidimensional Data Modeling | Solve | ||||
Medium Optimizing Query Performance | Solve | ||||
Easy Healthcare System | Solve | ||||
Hard ER Diagram and minimum tables | Solve | ||||
Medium Normalization Process | Solve | ||||
Medium University Courses | Solve | ||||
| 🧐 Question | 🔧 Skill | ||
|---|---|---|---|
Medium Data Merging | 2 mins ETL | Solve | |
Medium Data Updates | 2 mins ETL | Solve | |
Medium SQL in ETL Process | 3 mins ETL | Solve | |
Medium Trade Index | 3 mins ETL | Solve | |
Medium Multi Select | 2 mins SQL | Solve | |
Medium nth highest sales | 3 mins SQL | Solve | |
Medium Select & IN | 3 mins SQL | Solve | |
Medium Sorting Ubers | 3 mins SQL | Solve | |
Hard With, AVG & SUM | 2 mins SQL | Solve | |
Medium Marketing Database | 2 mins Data Warehouse | Solve | |
Medium Multidimensional Data Modeling | 2 mins Data Warehouse | Solve | |
Medium Optimizing Query Performance | 2 mins Data Warehouse | Solve | |
Easy Healthcare System | 2 mins Data Modeling | Solve | |
Hard ER Diagram and minimum tables | 2 mins Data Modeling | Solve | |
Medium Normalization Process | 3 mins Data Modeling | Solve | |
Medium University Courses | 2 mins Data Modeling | Solve |
| 🧐 Question | 🔧 Skill | 💪 Difficulty | ⌛ Time | ||
|---|---|---|---|---|---|
Data Merging | ETL | Medium | 2 mins | Solve | |
Data Updates | ETL | Medium | 2 mins | Solve | |
SQL in ETL Process | ETL | Medium | 3 mins | Solve | |
Trade Index | ETL | Medium | 3 mins | Solve | |
Multi Select | SQL | Medium | 2 mins | Solve | |
nth highest sales | SQL | Medium | 3 mins | Solve | |
Select & IN | SQL | Medium | 3 mins | Solve | |
Sorting Ubers | SQL | Medium | 3 mins | Solve | |
With, AVG & SUM | SQL | Hard | 2 mins | Solve | |
Marketing Database | Data Warehouse | Medium | 2 mins | Solve | |
Multidimensional Data Modeling | Data Warehouse | Medium | 2 mins | Solve | |
Optimizing Query Performance | Data Warehouse | Medium | 2 mins | Solve | |
Healthcare System | Data Modeling | Easy | 2 mins | Solve | |
ER Diagram and minimum tables | Data Modeling | Hard | 2 mins | Solve | |
Normalization Process | Data Modeling | Medium | 3 mins | Solve | |
University Courses | Data Modeling | Medium | 2 mins | Solve |
Con Adaface, pudimos optimizar nuestro proceso de selección inicial en más de un 75 %, liberando un tiempo precioso tanto para los gerentes de contratación como para nuestro equipo de adquisición de talentos.
Brandon Lee, jefe de personas, Love, Bonito
The most important thing while implementing the pre-employment Prueba de evaluación ETL in your hiring process is that it is an elimination tool, not a selection tool. In other words: you want to use the test to eliminate the candidates who do poorly on the test, not to select the candidates who come out at the top. While they are super valuable, pre-employment tests do not paint the entire picture of a candidate’s abilities, knowledge, and motivations. Multiple easy questions are more predictive of a candidate's ability than fewer hard questions. Harder questions are often "trick" based questions, which do not provide any meaningful signal about the candidate's skillset.
Science behind Adaface testsEmail invites: You can send candidates an email invite to the Prueba de evaluación ETL from your dashboard by entering their email address.
Public link: You can create a public link for each test that you can share with candidates.
API or integrations: You can invite candidates directly from your ATS by using our pre-built integrations with popular ATS systems or building a custom integration with your in-house ATS.
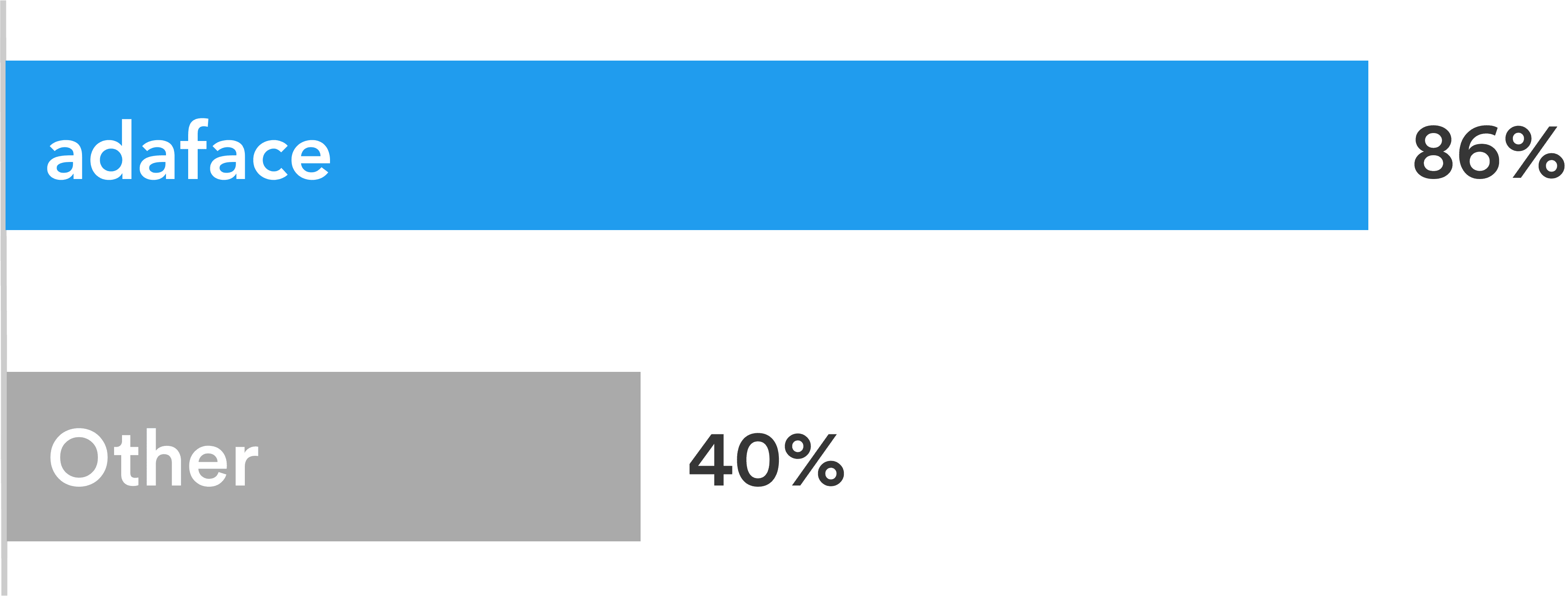
Adaface tests are conversational, low-stress, and take just 25-40 mins to complete.
This is why Adaface has the highest test-completion rate (86%), which is more than 2x better than traditional assessments.
ChatGPT protection
Screen proctoring
Plagiarism detection
Non-googleable questions
User authentication
IP proctoring
Web proctoring
Webcam proctoring
Full screen proctoring
Copy paste protection
Los gerentes de contratación sintieron que a través de las preguntas técnicas que hicieron durante las entrevistas del panel, pudieron decir qué candidatos tenían mejores puntajes y diferenciarse de aquellos que no obtuvieron tan buenos puntajes. Ellos son altamente satisfecho con la calidad de los candidatos preseleccionados con la selección de Adaface.
Sí. Apoyamos la detección de múltiples habilidades en una sola prueba. Puede revisar nuestra prueba SQL estándar para comprender qué tipo de preguntas usamos para evaluar las habilidades SQL. Una vez que se registre para cualquier plan, puede solicitar una evaluación personalizada que se personalice a la descripción de su trabajo. La evaluación personalizada incluirá preguntas para todas las habilidades imprescindibles requeridas para su rol de ETL.
Si, absolutamente. Las evaluaciones personalizadas se configuran en función de la descripción de su trabajo e incluirán preguntas sobre todas las habilidades imprescindibles que especifique.
Tenemos las siguientes características anti-trate en su lugar:
Lea más sobre las funciones de procuración.
Lo principal a tener en cuenta es que una evaluación es una herramienta de eliminación, no una herramienta de selección. Una evaluación de habilidades está optimizada para ayudarlo a eliminar a los candidatos que no están técnicamente calificados para el rol, no está optimizado para ayudarlo a encontrar el mejor candidato para el papel. Por lo tanto, la forma ideal de usar una evaluación es decidir un puntaje umbral (generalmente del 55%, lo ayudamos a comparar) e invitar a todos los candidatos que obtienen un puntaje por encima del umbral para las próximas rondas de la entrevista.
Cada evaluación de AdaFace está personalizada para su descripción de trabajo/ persona candidata ideal (nuestros expertos en la materia elegirán las preguntas correctas para su evaluación de nuestra biblioteca de más de 10000 preguntas). Esta evaluación se puede personalizar para cualquier nivel de experiencia.
Sí, te hace mucho más fácil comparar los candidatos. Las opciones para las preguntas de MCQ y el orden de las preguntas son aleatorizados. Tenemos características anti-trato/procuración en su lugar. En nuestro plan empresarial, también tenemos la opción de crear múltiples versiones de la misma evaluación con cuestiones de niveles de dificultad similares.
No. Desafortunadamente, no apoyamos las pruebas de práctica en este momento. Sin embargo, puede usar nuestras preguntas de muestra para la práctica.
Puede consultar nuestros planes de precios.
Sí, puede registrarse gratis y previsualice esta prueba.
Aquí hay una guía rápida sobre cómo solicitar una evaluación personalizada en Adaface.