
10 basic Kubernetes interview questions and answers to assess candidates
10 intermediate Kubernetes interview questions and answers to ask mid-tier administrators
8 Kubernetes interview questions and answers related to networking

Hiring the right Kubernetes professionals is crucial for organizations leveraging containerized applications and microservices architectures. Effective interview questions help recruiters and hiring managers assess candidates' knowledge, experience, and problem-solving abilities in Kubernetes ecosystems.
This blog post provides a comprehensive list of Kubernetes interview questions, ranging from basic to advanced topics. We cover questions for junior administrators, mid-tier administrators, and explore areas such as Kubernetes architecture, processes, and networking.
By using these questions, you can evaluate candidates' Kubernetes expertise and make informed hiring decisions. For a more thorough assessment of candidates, consider using a pre-employment Kubernetes skills test before conducting interviews.
Table of contents
10 basic Kubernetes interview questions and answers to assess candidates
10 Kubernetes interview questions to ask junior administrators
10 intermediate Kubernetes interview questions and answers to ask mid-tier administrators
12 Kubernetes interview questions about architecture
10 Kubernetes interview questions about processes
8 Kubernetes interview questions and answers related to networking
Which Kubernetes skills should you evaluate during the interview phase?
Hire top talent with Kubernetes skills tests and the right interview questions
Download Kubernetes interview questions template in multiple formats
10 basic Kubernetes interview questions and answers to assess candidates

Ready to dive into the world of Kubernetes? These 10 basic interview questions will help you assess candidates' foundational knowledge and problem-solving skills. Use this list to gauge their understanding of key concepts and their ability to apply them in real-world scenarios. Remember, the goal is to spark meaningful discussions, not to stump your candidates!
1. Can you explain what Kubernetes is and why it's important?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It's important because it simplifies the process of managing complex, distributed systems at scale.
A strong candidate should highlight Kubernetes' ability to handle load balancing, storage orchestration, automated rollouts and rollbacks, and self-healing capabilities. They might also mention its portability across different cloud providers and on-premises environments.
Look for answers that demonstrate an understanding of how Kubernetes solves real-world problems in modern application deployment and management. Follow up by asking about specific features they find most valuable in their experience.
2. What's the difference between a pod and a container in Kubernetes?
A pod is the smallest deployable unit in Kubernetes, while a container is a lightweight, standalone executable package that includes everything needed to run a piece of software. The key difference is that a pod can contain one or more containers that share the same network namespace and storage.
Candidates should explain that pods provide a higher-level abstraction for managing related containers. They might mention that pods are scheduled together, share the same lifecycle, and can communicate with each other using localhost.
Look for answers that demonstrate an understanding of the container orchestration hierarchy in Kubernetes. Consider asking follow-up questions about scenarios where multiple containers in a pod would be beneficial.
3. How would you handle a situation where a pod keeps crashing?
When dealing with a repeatedly crashing pod, a systematic troubleshooting approach is crucial. Candidates should mention steps like:
- Checking pod logs using 'kubectl logs' command
- Examining pod events with 'kubectl describe pod'
- Investigating container resource usage
- Reviewing application logs within the container
- Checking for any recent changes in deployments or configurations
Look for answers that demonstrate a methodical approach to problem-solving and familiarity with Kubernetes troubleshooting tools. Ideal candidates might also mention setting up proper monitoring and alerting to catch issues early.
4. Can you explain the concept of rolling updates in Kubernetes?
Rolling updates in Kubernetes allow for updating applications without downtime by gradually replacing old pods with new ones. This process ensures that the application remains available during the update, minimizing disruption to users.
A strong answer should explain that Kubernetes creates new pods with the updated version while simultaneously terminating old ones, maintaining the desired number of replicas. Candidates might mention the ability to control the rate of the update and automatically roll back if issues are detected.
Look for responses that demonstrate understanding of the benefits of rolling updates, such as zero-downtime deployments and the ability to easily revert changes. Consider asking about strategies for managing database schema changes during rolling updates.
5. What is a Kubernetes Service and why is it important?
A Kubernetes Service is an abstraction layer that defines a logical set of pods and a policy by which to access them. It provides a stable IP address and DNS name for a set of pods, allowing other parts of the application to interact with them without needing to know the specific pods' IP addresses.
Candidates should highlight that Services enable load balancing across multiple pod instances and provide service discovery within the cluster. They might mention different types of Services like ClusterIP, NodePort, and LoadBalancer.
Look for answers that demonstrate understanding of how Services facilitate communication between different parts of an application in a microservices architecture. Consider asking about scenarios where different types of Services would be appropriate.
6. How does Kubernetes handle network security between pods?
Kubernetes uses Network Policies to control traffic flow between pods. These policies allow you to specify how groups of pods are allowed to communicate with each other and other network endpoints.
A strong answer should mention that Network Policies are implemented by the network plugin, and they can restrict traffic based on namespaces, pod labels, IP blocks, and ports. Candidates might also discuss the default 'allow all' behavior and the importance of explicitly defining policies for better security.
Look for responses that demonstrate an understanding of the balance between security and functionality in a Kubernetes environment. Consider asking about strategies for implementing least-privilege access in a microservices architecture.
7. What is a Kubernetes Ingress and when would you use it?
A Kubernetes Ingress is an API object that manages external access to services in a cluster, typically HTTP. It provides load balancing, SSL termination, and name-based virtual hosting.
Candidates should explain that Ingress is used when you need to expose multiple services under a single IP address, often to implement complex routing rules. They might mention that Ingress requires an Ingress controller to function.
Look for answers that demonstrate understanding of how Ingress simplifies external access management compared to using multiple LoadBalancer services. Consider asking about different Ingress controllers they've worked with and their pros and cons.
8. How do you manage application secrets in Kubernetes?
Kubernetes provides a Secret object for storing and managing sensitive information such as passwords, OAuth tokens, and SSH keys. Secrets are stored in etcd and can be mounted as files in pods or used as environment variables.
A strong answer should mention that Secrets are base64 encoded but not encrypted by default, and discuss additional security measures like encryption at rest, RBAC for access control, and potentially integrating with external secret management systems.
Look for responses that demonstrate awareness of security best practices in Kubernetes environments. Consider asking about strategies for rotating secrets or handling secrets across different environments (dev, staging, production).
9. Can you explain the concept of Kubernetes namespaces?
Kubernetes namespaces are a way to divide cluster resources between multiple users, teams, or projects. They provide a scope for names, allowing you to organize and isolate resources within a cluster.
Candidates should mention that namespaces can be used for resource quotas, network policies, and access control. They might discuss the default namespaces (default, kube-system, kube-public) and scenarios where creating custom namespaces is beneficial.
Look for answers that demonstrate understanding of how namespaces contribute to multi-tenancy and resource management in Kubernetes. Consider asking about strategies for managing applications across multiple namespaces or clusters.
10. How would you approach scaling a Kubernetes application?
Scaling a Kubernetes application involves adjusting the number of pod replicas to handle changes in load. This can be done manually using the 'kubectl scale' command or automatically using Horizontal Pod Autoscaler (HPA).
A strong answer should discuss both horizontal scaling (adding more pods) and vertical scaling (increasing resources for existing pods). Candidates might mention considerations like monitoring application metrics, setting resource requests and limits, and using node autoscaling for cluster-level scaling.
Look for responses that demonstrate understanding of the cloud-native approach to application scaling. Consider asking about strategies for handling stateful applications or database scaling in Kubernetes.
10 Kubernetes interview questions to ask junior administrators
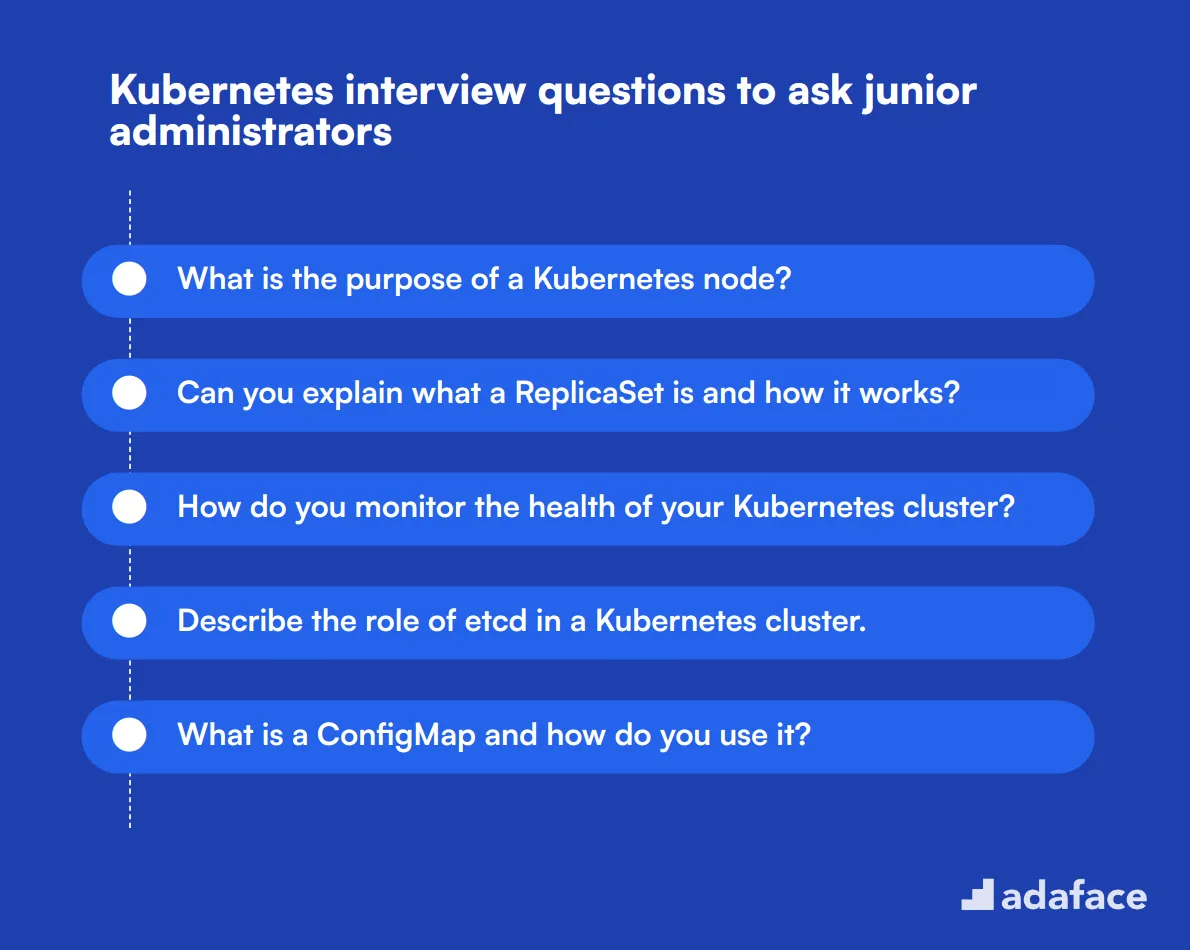
To assess a junior administrator’s foundational knowledge of Kubernetes, use this tailored list of interview questions. These questions can help you gauge their technical understanding and readiness to tackle real-world scenarios in a Kubernetes environment. For more insights on job roles, check out this Kubernetes Engineer job description.
- What is the purpose of a Kubernetes node?
- Can you explain what a ReplicaSet is and how it works?
- How do you monitor the health of your Kubernetes cluster?
- Describe the role of etcd in a Kubernetes cluster.
- What is a ConfigMap and how do you use it?
- How would you troubleshoot a deployment issue in Kubernetes?
- What is the difference between a StatefulSet and a Deployment?
- Can you explain the role of kubelet in a Kubernetes cluster?
- What steps would you take to upgrade a Kubernetes cluster?
- How do you implement resource limits and requests in Kubernetes?
10 intermediate Kubernetes interview questions and answers to ask mid-tier administrators

Ready to level up your Kubernetes hiring game? These 10 intermediate questions are perfect for assessing mid-tier administrators. They'll help you gauge a candidate's practical knowledge and problem-solving skills without getting too deep into the technical weeds. Use them to spark insightful discussions and uncover how well your potential hires can navigate the Kubernetes ecosystem.
1. How would you approach debugging a pod that's in a CrashLoopBackOff state?
When a pod is in a CrashLoopBackOff state, it means the container is starting, crashing, then restarting repeatedly. To debug this issue, I would take the following steps:
- Check the pod logs using 'kubectl logs' to see if there are any error messages.
- Use 'kubectl describe pod' to get more details about the pod's status and events.
- Verify the pod's resource limits and requests to ensure it's not being terminated due to resource constraints.
- Check if there are any issues with the container image or its configuration.
- Investigate any dependencies or external services the pod might be trying to connect to.
Look for candidates who demonstrate a systematic approach to troubleshooting. They should mention the importance of gathering information before making changes and show familiarity with Kubernetes debugging tools.
2. Can you explain the difference between a DaemonSet and a Deployment?
DaemonSets and Deployments are both controllers in Kubernetes, but they serve different purposes:
- DaemonSet: Ensures that a copy of a pod runs on all (or some) nodes in the cluster. It's useful for node-level operations like log collection or monitoring.
- Deployment: Manages a set of identical pods, allowing for easy scaling and updates. It's ideal for stateless applications that can run on any node.
A strong candidate should be able to provide examples of when to use each controller. For instance, they might mention using a DaemonSet for a node monitoring agent and a Deployment for a web application. Look for understanding of the use cases and limitations of each.
3. How do you handle persistent storage in Kubernetes?
Handling persistent storage in Kubernetes involves using PersistentVolumes (PVs) and PersistentVolumeClaims (PVCs). Here's a brief overview:
- PersistentVolumes are cluster resources that represent physical storage.
- PersistentVolumeClaims are requests for storage by users.
- StorageClasses can be used to dynamically provision PVs.
- Pods can then mount these PVCs as volumes.
Look for candidates who understand the relationship between PVs and PVCs, and can explain how StorageClasses facilitate dynamic provisioning. They should also be able to discuss considerations like data persistence across pod restarts and potential storage types (e.g., cloud provider storage, NFS).
4. What strategies would you use to optimize resource utilization in a Kubernetes cluster?
Optimizing resource utilization in a Kubernetes cluster involves several strategies:
- Use resource requests and limits to ensure efficient pod scheduling.
- Implement horizontal pod autoscaling to adjust replica count based on metrics.
- Utilize vertical pod autoscaling to automatically adjust CPU and memory requests.
- Use node auto-provisioning to automatically add or remove nodes based on cluster demand.
- Implement pod disruption budgets to maintain application availability during cluster changes.
- Use pod affinity and anti-affinity rules to optimize pod placement.
A strong candidate should be able to explain the benefits and potential drawbacks of each strategy. They should also demonstrate an understanding of how these strategies can be combined to create a comprehensive resource optimization plan.
5. How would you implement a blue-green deployment in Kubernetes?
A blue-green deployment in Kubernetes involves running two identical environments (blue and green) and switching traffic between them. Here's a general approach:
- Create two identical deployments (blue and green) with different labels.
- Use a service with a selector matching the blue deployment's labels.
- Update the green deployment with the new version of the application.
- Test the green deployment to ensure it's working correctly.
- Update the service selector to match the green deployment's labels, switching traffic.
- If issues arise, switch back to the blue deployment by updating the service selector.
Look for candidates who understand the benefits of this approach, such as zero-downtime deployments and easy rollbacks. They should also be able to discuss potential challenges, like managing persistent data or stateful applications in this scenario.
6. Explain the concept of Kubernetes Operators and when you might use them.
Kubernetes Operators are software extensions to Kubernetes that make use of custom resources to manage applications and their components. They essentially automate the management of complex, stateful applications.
Operators are useful for applications that require specialized knowledge to deploy and operate. They encapsulate this domain knowledge and extend the Kubernetes API to create, configure, and manage instances of complex applications on behalf of Kubernetes users.
Look for candidates who can provide examples of when to use Operators, such as for managing databases, monitoring systems, or other complex, stateful applications. They should understand that Operators help automate tasks like backups, upgrades, and failure recovery, which would otherwise require manual intervention.
7. How would you secure communication between microservices in a Kubernetes cluster?
Securing communication between microservices in a Kubernetes cluster involves several strategies:
- Use Network Policies to control traffic flow between pods.
- Implement mutual TLS (mTLS) for service-to-service authentication and encryption.
- Utilize a service mesh like Istio or Linkerd for advanced traffic management and security features.
- Use Kubernetes Secrets to manage sensitive information like certificates.
- Implement RBAC (Role-Based Access Control) to manage access to the Kubernetes API.
- Regularly update and patch all components, including the Kubernetes version and container images.
A strong candidate should be able to explain the benefits and potential drawbacks of each approach. They should also demonstrate an understanding of the DevOps principles that underpin these security practices, such as the importance of automation and continuous monitoring.
8. What is a Kubernetes Admission Controller and how would you use it?
A Kubernetes Admission Controller is a piece of code that intercepts requests to the Kubernetes API server before the persistence of the object, but after the request is authenticated and authorized. It can be used to validate, mutate, or reject requests based on custom logic.
Some common use cases for Admission Controllers include:
- Enforcing security policies (e.g., preventing privileged containers)
- Resource management (e.g., enforcing resource quotas or limits)
- Automatically adding labels or annotations to resources
- Validating or mutating custom resources
Look for candidates who can explain the difference between validating and mutating admission controllers. They should also be able to discuss potential drawbacks, such as the impact on API server performance if not implemented carefully.
9. How would you implement auto-scaling in Kubernetes based on custom metrics?
Implementing auto-scaling in Kubernetes based on custom metrics involves several steps:
- Set up a metrics server to collect custom metrics.
- Create a Horizontal Pod Autoscaler (HPA) that references these custom metrics.
- Configure the HPA with scaling rules based on the custom metrics.
- Ensure the application exposes the relevant metrics.
- Monitor and fine-tune the autoscaling behavior.
A strong candidate should be able to discuss different types of custom metrics (e.g., application-specific metrics, business metrics) and how they can be collected and exposed to Kubernetes. They should also understand the limitations of custom metric autoscaling and potential alternatives like the Vertical Pod Autoscaler or cluster autoscaler.
10. Explain the concept of Kubernetes Finalizers and when you might use them.
Kubernetes Finalizers are namespaced keys that tell Kubernetes to wait until specific conditions are met before it fully deletes resources marked for deletion. They are used to implement pre-delete hooks.
Finalizers are useful in scenarios where you need to perform cleanup operations before a resource is deleted. For example:
- Cleaning up external dependencies
- Releasing resources that are not automatically released by Kubernetes
- Performing custom validation before allowing deletion
Look for candidates who understand that finalizers can prevent resource deletion if not handled properly. They should be able to discuss best practices, such as implementing timeout mechanisms and ensuring finalizers are removed once their work is complete.
12 Kubernetes interview questions about architecture

To determine whether your candidates comprehend the foundational elements of Kubernetes architecture, ask them some of these 12 Kubernetes interview questions about architecture. These questions are designed to help you identify the skills required for Kubernetes engineers, ensuring you find the right fit for your team.
- Can you describe the architecture of the Kubernetes control plane?
- What are the primary components of a Kubernetes cluster and their roles?
- How does Kubernetes achieve high availability for its components?
- Can you explain the function of a Kubernetes API server?
- How does Kubernetes handle scheduling of pods onto nodes?
- What is the role of a controller manager in Kubernetes?
- How does the Kubernetes scheduler work, and what factors does it consider?
- What is the purpose of the cluster DNS in Kubernetes?
- How does kube-proxy facilitate networking in a Kubernetes cluster?
- Can you explain the concept of taints and tolerations in Kubernetes?
- What mechanisms does Kubernetes use for service discovery?
- How does Kubernetes manage configuration and secrets at the architectural level?
10 Kubernetes interview questions about processes
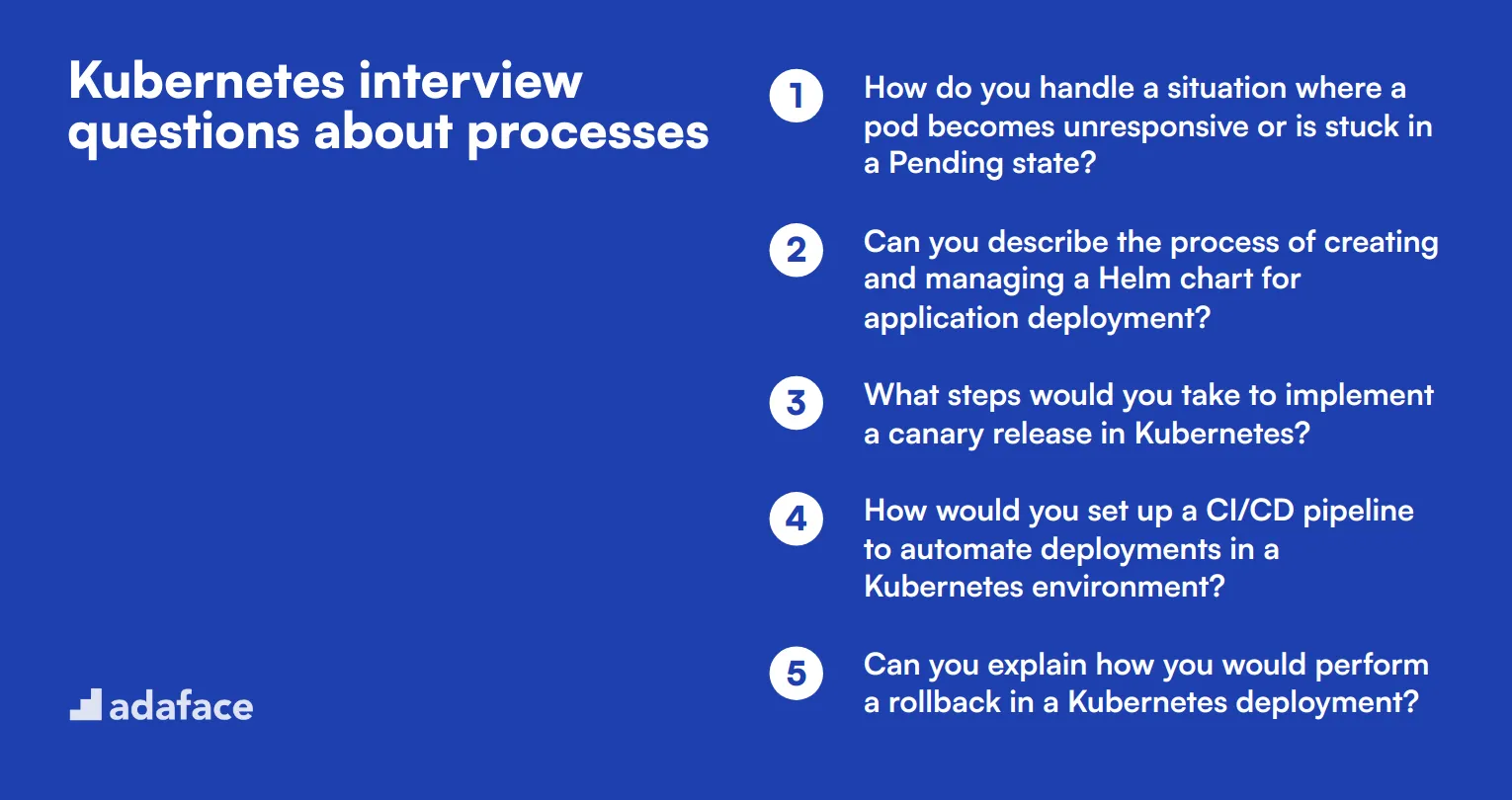
To evaluate candidates' ability to manage and optimize processes within a Kubernetes environment, consider using these targeted questions. They're designed to help you assess practical skills and real-world problem-solving capabilities that are essential for a successful Kubernetes engineer or DevOps specialist. For a deeper understanding, check out our Kubernetes engineer job description.
- How do you handle a situation where a pod becomes unresponsive or is stuck in a Pending state?
- Can you describe the process of creating and managing a Helm chart for application deployment?
- What steps would you take to implement a canary release in Kubernetes?
- How would you set up a CI/CD pipeline to automate deployments in a Kubernetes environment?
- Can you explain how you would perform a rollback in a Kubernetes deployment?
- What strategies would you use to ensure zero downtime during application updates in Kubernetes?
- How do you manage inter-pod communication in a multi-tenant Kubernetes cluster?
- What methods would you use to gather metrics and logs from your Kubernetes applications?
- How do you ensure compatibility and versioning when deploying microservices in Kubernetes?
- Can you explain the concept of pod disruption budgets and their importance in managing availability?
8 Kubernetes interview questions and answers related to networking

To help you assess whether candidates have a firm grasp on Kubernetes networking, use these targeted interview questions. These questions will help you gauge their understanding of crucial networking concepts, ensuring they can effectively manage and troubleshoot network-related issues in a Kubernetes environment.
1. Can you explain how Kubernetes manages internal and external traffic?
Kubernetes manages internal and external traffic using a combination of services, Ingress controllers, and network policies. Internal traffic often relies on ClusterIP services, which make a service accessible only within the Kubernetes cluster. For external traffic, NodePort and LoadBalancer services are used to expose services outside the cluster.
An ideal candidate will mention the different types of services and how they are used to route traffic. Look for answers that show an understanding of Kubernetes Services and their roles in managing traffic.
2. What is a Network Policy in Kubernetes and why is it important?
A Network Policy in Kubernetes defines how groups of pods are allowed to communicate with each other and other network endpoints. It's crucial for network security, as it allows you to control the traffic flow at the IP address or port level within the cluster.
The ideal answer should highlight the importance of Network Policies for implementing security controls and segmenting network traffic within the cluster. Look for candidates who can explain how to define and apply these policies effectively.
3. How does Kubernetes ensure network isolation between different namespaces?
Kubernetes ensures network isolation between different namespaces using Network Policies. By default, all pods within a cluster can communicate with each other. Network Policies can be applied to restrict traffic between namespaces, ensuring that only authorized traffic is allowed.
A strong response will include an explanation of how Network Policies are used to create boundaries between namespaces. Look for candidates who understand the importance of network isolation for security and compliance.
4. Can you describe the role of a Service Mesh in a Kubernetes environment?
A Service Mesh is a dedicated infrastructure layer designed to handle service-to-service communications. In a Kubernetes environment, it provides functionalities like traffic management, load balancing, service discovery, and security. Examples of popular service mesh implementations include Istio and Linkerd.
The ideal candidate should mention the benefits of using a Service Mesh, such as improved observability, security, and reliability. They should also be able to discuss scenarios where a Service Mesh would be advantageous.
5. What are the different types of services in Kubernetes and when would you use each?
Kubernetes offers several types of services: ClusterIP, NodePort, LoadBalancer, and ExternalName. ClusterIP is used for internal communication within the cluster. NodePort exposes the service on a static port on each node's IP. LoadBalancer uses an external load balancer to expose the service to the internet. ExternalName maps a service to a DNS name.
An ideal response will include practical examples of when to use each type of service. Look for candidates who can articulate the differences and appropriate use cases for each service type.
6. How do you troubleshoot networking issues in a Kubernetes cluster?
Troubleshooting networking issues in Kubernetes often involves several steps: checking pod and service configurations, verifying network policies, and using tools like kubectl, tcpdump, and network plugins. It's essential to diagnose where the traffic is failing and isolate the issue.
A strong candidate will discuss specific steps and tools they would use for troubleshooting. Look for answers that demonstrate a methodical approach to identifying and resolving network issues.
7. What is CNI (Container Network Interface) and how does it work in Kubernetes?
CNI (Container Network Interface) is a framework for configuring network interfaces in Linux containers. In Kubernetes, CNI plugins are used to set up networking for pods. These plugins manage IP allocation, routing, and connectivity between pods.
Candidates should explain how CNI plugins integrate with Kubernetes to provide flexible and scalable networking solutions. Look for knowledge about different CNI plugins like Calico, Flannel, and Weave, and their specific use cases.
8. How does Kubernetes handle DNS resolution within a cluster?
Kubernetes uses a DNS service to automatically create DNS records for services and pods. This allows applications within the cluster to communicate with each other using standard DNS names. The CoreDNS add-on is a common implementation for DNS in Kubernetes.
The ideal answer will include details on how DNS resolution simplifies service discovery and communication within the cluster. Candidates should also mention potential issues and troubleshooting steps related to DNS in Kubernetes.
Which Kubernetes skills should you evaluate during the interview phase?
Conducting a single interview may not enable you to gauge all the aspects of a candidate's expertise. However, focusing on core Kubernetes skills can help you make more informed hiring decisions. Here are the essential Kubernetes skills to evaluate during the interview phase.

Container Orchestration
You can assess this skill using an assessment test with relevant MCQs. These questions are designed to filter out candidates who have a thorough understanding of container orchestration.
In addition to MCQs, you can also ask targeted interview questions. Here's one question you can ask to judge this skill:
Can you explain how Kubernetes manages the lifecycle of a pod?
Look for candidates who can describe the different phases of a pod's lifecycle and how Kubernetes handles scaling and self-healing of pods.
Networking
Use an assessment test with relevant MCQs to evaluate a candidate's networking knowledge. These tests can help you identify candidates who understand Kubernetes networking.
To drill further into their understanding, you can ask specific interview questions. For example:
What is a Kubernetes Service, and how does it work?
Expect answers that cover the types of services (ClusterIP, NodePort, LoadBalancer) and details about how services enable communication between pods and external services.
Storage Management
Consider using an assessment test with relevant MCQs to gauge a candidate's knowledge on storage management. Relevant questions will help filter out those who understand persistent volumes and claims.
You can also ask targeted questions during the interview to assess this skill. One relevant question could be:
How do you manage persistent storage in Kubernetes?
Look for candidates who can explain the concept of Persistent Volumes (PVs) and Persistent Volume Claims (PVCs) and how they are used to manage stateful applications.
Hire top talent with Kubernetes skills tests and the right interview questions
When hiring for Kubernetes roles, ensuring candidates possess the necessary skills is crucial. A thorough assessment helps you identify individuals who can effectively manage and orchestrate containerized applications.
One of the most effective ways to gauge these skills is through skill tests. Consider utilizing our Kubernetes online test to evaluate candidates accurately.
After conducting the test, you can easily shortlist the best applicants based on their performance. This enables you to focus your interview efforts on the most qualified candidates.
To get started, visit our test library to explore more options. Sign up today and streamline your hiring process.
Kubernetes Online Test
25 mins | 10 MCQs
The Kubernetes Online Test uses scenario-based MCQs to evaluate candidates on their knowledge of Kubernetes architecture, setup, deployment, networking, and troubleshooting. Additionally, the test evaluates the candidate's knowledge of Kubernetes resource objects, Kubernetes API, Kubernetes security and authentication, and Kubernetes upgrades.
Try Kubernetes Online Test
Download Kubernetes interview questions template in multiple formats

Kubernetes Interview Questions FAQs
What skill levels do these Kubernetes interview questions cover?
The questions cover basic, junior, intermediate, and advanced levels, including topics on architecture, processes, and networking.
How can I use these questions in my hiring process?
Use them to assess candidates' knowledge during interviews, tailoring the difficulty to the position you're hiring for.
Are there sample answers provided for the interview questions?
Yes, the post includes answers for many of the questions to help interviewers evaluate responses.
How can I complement these interview questions in my hiring process?
Consider using Kubernetes skills tests alongside these questions for a more thorough evaluation of candidates.
40 min skill tests.
No trick questions.
Accurate shortlisting.
We make it easy for you to find the best candidates in your pipeline with a 40 min skills test.
Try for freeRelated posts
Free resources

Join 1200+ companies in 80+ countries.
Try the most candidate friendly skills assessment tool today.

40 min tests.
No trick questions.
Accurate shortlisting.
No trick questions.
Accurate shortlisting.