

As a recruiter, you know that hiring a Site Reliability Engineer (SRE) is vital for ensuring seamless operations and high availability in technology-driven companies. SREs bridge the gap between development and operations, focusing on reliability and performance. Many companies, however, struggle to hire the right SREs because they overlook the specific skills and cultural fit required for this critical role.
In this article, we explore what an SRE is, the skills they need, and how to successfully hire one. We discuss the hiring process, skills tests, and platforms to find top talent. To better understand the skill set required, you can refer to our detailed guide on skills required for Site Reliability Engineers.
Table of contents
Why Hire a Site Reliability Engineer?
What does a Site Reliability Engineer do?
Site Reliability Engineer Hiring Process
Skills and Qualifications to Look for in a Site Reliability Engineer
Top Platforms to Hire Site Reliability Engineers
Keywords to Look for in Site Reliability Engineer Resumes
Recommended Skills Tests to Screen Site Reliability Engineers
Structuring Technical Interviews for Site Reliability Engineers
Understanding the Cost of Hiring a Site Reliability Engineer
What's the difference between a Site Reliability Engineer and a DevOps Engineer?
What are the ranks of Site Reliability Engineers?
Hire the Best Site Reliability Engineers with Confidence
Why Hire a Site Reliability Engineer?
Site Reliability Engineers (SREs) are key to maintaining the health and performance of complex systems. They bridge the gap between development and operations, ensuring your services run smoothly and scale effectively. If your company faces frequent outages, slow deployment cycles, or struggles with system scalability, it's time to consider hiring an SRE.
SREs can help by:
- Implementing automation to reduce manual tasks and errors
- Designing and managing monitoring systems for early problem detection
- Improving incident response processes and reducing downtime
Before hiring a full-time SRE, assess your current infrastructure needs and growth plans. For smaller companies or those new to SRE practices, starting with a consultant can be a good way to evaluate the skills required for a Site Reliability Engineer and determine if a full-time role is necessary.
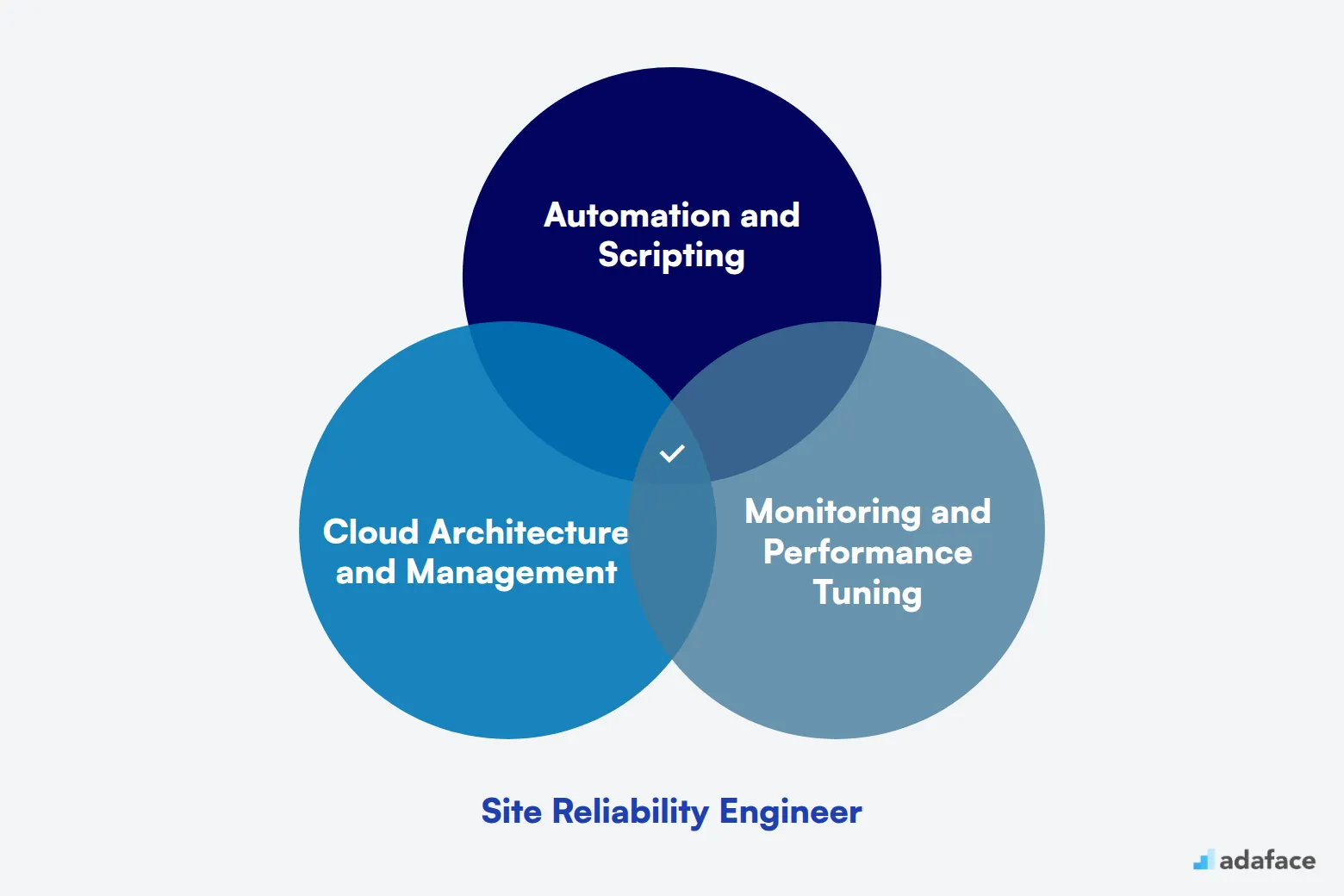
What does a Site Reliability Engineer do?
A Site Reliability Engineer (SRE) bridges the gap between development and operations teams. They focus on creating scalable and highly reliable software systems, ensuring that applications and services remain available, performant, and secure.
The day-to-day responsibilities of an SRE include:
- Monitoring system performance and responding to incidents
- Implementing automation to reduce manual tasks and improve efficiency
- Collaborating with developers to optimize application performance
- Managing and scaling infrastructure to meet growing demands
- Conducting post-mortems to learn from failures and prevent future issues
- Implementing and maintaining disaster recovery plans
Site Reliability Engineer Hiring Process
Hiring a Site Reliability Engineer (SRE) can be a meticulous process, typically taking around 1-2 months. It involves several key steps to ensure you find the right fit for your organization.
- Define the Job Description: Start with a clear and detailed job description. This sets the foundation for attracting suitable candidates.
- Posting and Initial Applications: Publish the job on relevant platforms. Expect to receive applications within the first week.
- Resume Screening: Shortlist candidates based on their resumes. This may take about a week, depending on the volume of applicants.
- Skill Assessment: Conduct skill tests relevant to SRE tasks. This could include practical scenarios or case studies, taking another week or so.
- Interviews: Move shortlisted candidates to the interview stage. Assess their technical and soft skills.
- Offer Stage: Finally, extend an offer to the best candidate. This structured approach helps streamline the hiring process and ensures you select the most qualified individual for the role.
In summary, the hiring process for an SRE generally spans 1-2 months, allowing ample time for each step from defining job requirements to making an offer. Expect some flexibility in timelines based on your specific needs and candidate availability. Now, let’s explore each of these steps in detail to ensure a smooth hiring experience.
Skills and Qualifications to Look for in a Site Reliability Engineer
Before kicking off the hiring process, it's important to craft the ideal candidate profile for a Site Reliability Engineer at your company. One common mistake is not distinguishing between must-have skills and nice-to-have skills. Customizing your expectations helps in attracting the right talent. For instance, while some companies might need deep expertise in a specific cloud platform, others might focus more on scripting skills.
To start, consider what's necessary. Required skills might include a Bachelor’s degree in Computer Science or a related field, and at least three years of SRE experience. Scripting in languages like Python, Bash, or Ruby often proves invaluable, as do skills in cloud platforms such as AWS or Google Cloud. Familiarity with infrastructure as code tools like Terraform also tends to be crucial.
On the flip side, preferred skills can set a candidate apart but aren't mandatory. Experience with container orchestration tools like Kubernetes, understanding of CI/CD pipelines, or familiarity with monitoring tools like Prometheus could provide added value. Also, operating successfully in a fast-paced, team-oriented environment can be a big plus.
For more insights on aligning skills with roles, explore Adaface's skill mapping. This resource helps in ensuring your expectations align with the industry's demands.
| Required skills and qualifications | Preferred skills and qualifications |
|---|---|
| Bachelor’s degree in Computer Science, Engineering, or a related technical field | Experience with container orchestration tools such as Kubernetes or Docker |
| 3+ years of experience as a Site Reliability Engineer or similar role | Familiarity with CI/CD pipelines and tools like Jenkins or GitLab CI |
| Strong scripting skills in languages such as Python, Bash, or Ruby | Understanding of networking concepts and protocols |
| Proficient in cloud platforms like AWS, Google Cloud, or Azure | Experience with monitoring and observability tools like Prometheus or Grafana |
| Experience with infrastructure as code tools like Terraform or Ansible | Proven success in a fast-paced, team-oriented environment |
Top Platforms to Hire Site Reliability Engineers
Now that you have a well-crafted job description, it's time to list your SRE position on job boards to attract qualified candidates. The right platform can make a significant difference in the quality and quantity of applicants you receive. Let's explore some of the best options for finding top SRE talent.
LinkedIn Jobs
Ideal for posting full-time SRE positions and reaching a wide network of professionals. Offers advanced search and filtering options for recruiters.
Indeed
Large job board with a broad reach. Suitable for posting various SRE roles and accessing a diverse pool of candidates.
Dice
Specialized in tech jobs. Excellent for targeting SREs with specific technical skills and experience.
Other notable platforms include AngelList for startup-focused SREs, Stack Overflow Jobs for reaching active members of the developer community, Hired for accessing a curated pool of tech talent, and FlexJobs for remote SRE positions. Each platform offers unique advantages, so consider your specific needs when choosing where to post your SRE job listing. Remember, a multi-platform approach often yields the best results in finding the right Site Reliability Engineer for your team.
Keywords to Look for in Site Reliability Engineer Resumes
Resume screening helps you quickly filter through numerous SRE applications. It's the first step in identifying candidates who match your job requirements.

Start by identifying key technical skills and experience. Look for keywords like Python, AWS, Kubernetes, and Terraform. Also, check for terms related to monitoring, CI/CD, and infrastructure as code.
AI tools can streamline your resume screening process. You can use ChatGPT or Claude with a custom prompt to analyze resumes based on your specific criteria and job requirements.
Here's a sample prompt for AI-powered resume screening:
TASK: Screen resumes for Site Reliability Engineer role
INPUT: Resumes
OUTPUT: For each resume, provide:
- Email
- Name
- Matching keywords
- Score (out of 10)
- Recommendation
- Shortlist (Yes, No, Maybe)
RULES:
- If unsure, mark as Maybe
- Keep recommendations concise
KEYWORDS:
- Cloud platforms (AWS, GCP, Azure)
- Scripting (Python, Bash, Ruby)
- Infrastructure as Code (Terraform, Ansible)
- Containerization (Kubernetes, Docker)
- Monitoring (Prometheus, Grafana)
- CI/CD (Jenkins, GitLab CI)
When screening resumes manually or using AI, focus on the top skills required for a Site Reliability Engineer. This approach will help you identify the most promising candidates for your SRE interview process.
Recommended Skills Tests to Screen Site Reliability Engineers
Skills tests are an effective way to evaluate the technical proficiency of Site Reliability Engineers. These tests are designed to objectively assess candidates' abilities and ensure they possess the right skills for the role. Below are our top recommendations for skills tests from our library:
Site Reliability Test: This test is tailored specifically for Site Reliability Engineers, focusing on their ability to maintain and enhance service reliability and performance.
DevOps Online Test: Since SRE and DevOps roles often overlap, this test evaluates candidates' understanding of DevOps practices, toolchains, and their ability to automate processes.
AWS DevOps Test: As many Site Reliability Engineers work in cloud environments, this test helps determine the candidate's proficiency with AWS, one of the leading cloud service providers.
Kubernetes Online Test: Given Kubernetes' prominence in container orchestration, this test assesses candidates' skills in managing and deploying containers using Kubernetes.
Linux Online Test: Since Linux is the underlying OS for many systems, this test gauges the candidate's ability to navigate, manage, and troubleshoot Linux-based environments.
Structuring Technical Interviews for Site Reliability Engineers
After candidates pass the initial skills tests, it's time for technical interviews to assess their hard skills in-depth. While skills tests are great for initial screening, technical interviews help identify the best candidates for the SRE role. Let's look at some key questions to ask during these interviews.
Consider asking: 'How would you design a scalable and reliable system?', 'Explain your approach to troubleshooting a production issue', 'How do you implement and manage monitoring and alerting?', 'Describe your experience with infrastructure as code', and 'How do you ensure security in cloud environments?'. These questions probe the candidate's problem-solving skills, system design knowledge, operational experience, automation capabilities, and security awareness - all critical for an SRE role.
Understanding the Cost of Hiring a Site Reliability Engineer
The cost to hire a Site Reliability Engineer can vary significantly depending on several factors such as location, experience, and the specific requirements of your organization. Generally, salaries in the U.S. range from $94,000 to $222,000, with the median around $144,500.
In addition to base salary, it's important to consider other expenses like benefits, bonuses, and potential relocation costs that could impact your overall budget. Ensuring that your compensation package is competitive will help you attract the right talent.
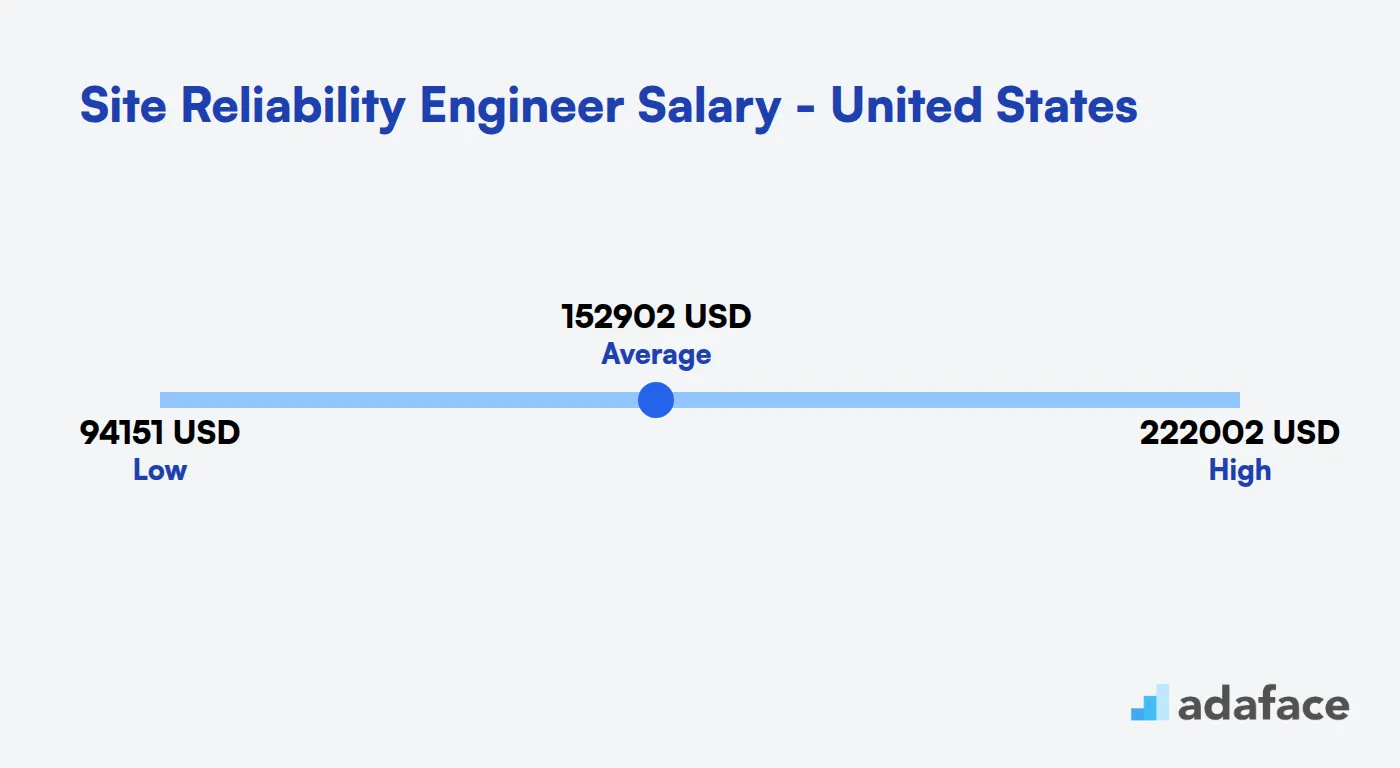
Site Reliability Engineer Salary in the United States
The average salary for Site Reliability Engineers in the United States ranges from $94,000 to $222,000, with a median of about $144,500. Top tech hubs like San Francisco, New York, and Seattle offer higher salaries, with medians around $170,000 to $176,000.
Factors influencing SRE salaries include location, experience, and company size. Cities like San Diego and Sunnyvale tend to offer competitive packages, while areas like Dallas and Atlanta typically have slightly lower ranges but still attractive compensation.
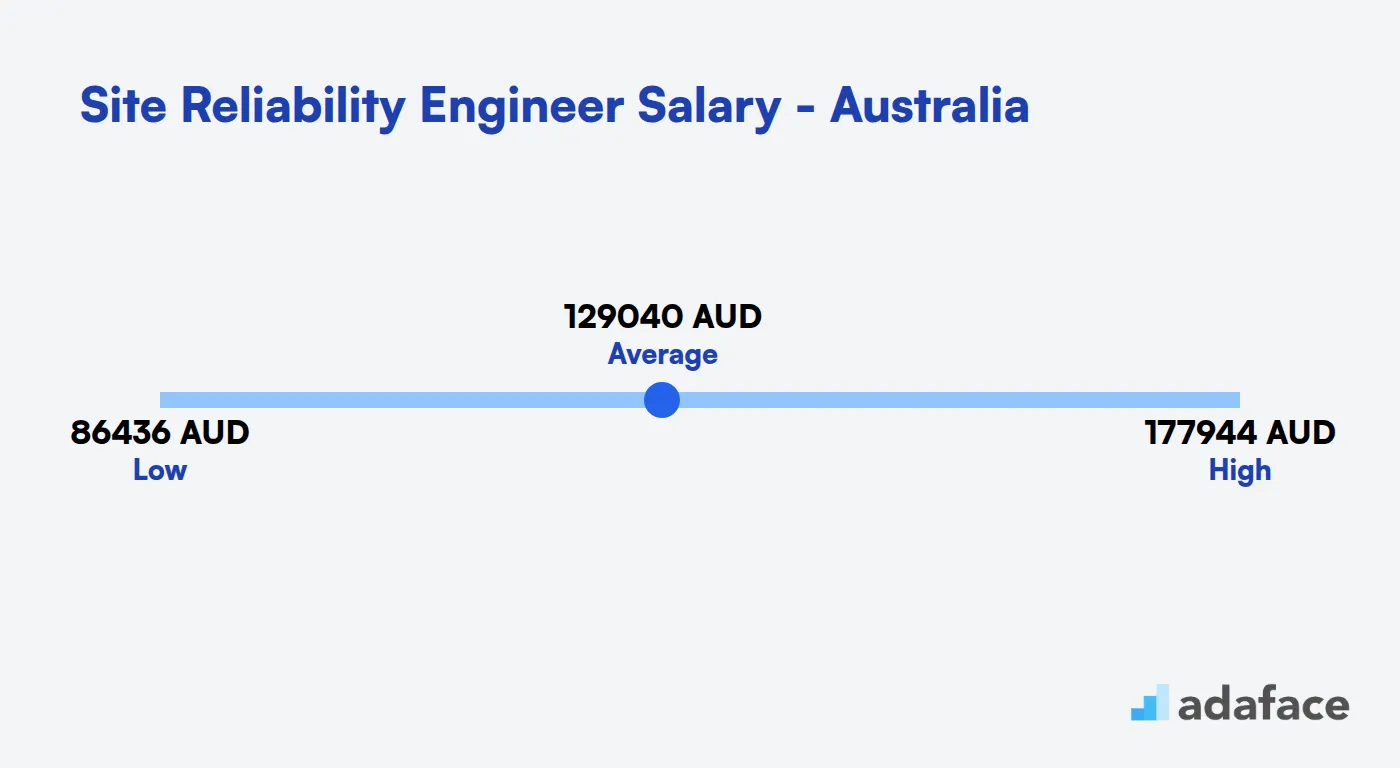
Site Reliability Engineer Salary in Australia
The average salary for Site Reliability Engineers in Australia ranges from AUD 86,437 to AUD 177,945, with a median of AUD 124,020. Brisbane offers the highest median salary at AUD 157,857, followed by Melbourne at AUD 149,834 and Sydney at AUD 144,315.
Salaries can vary based on location, experience, and company size. Major cities like Sydney, Melbourne, and Brisbane tend to offer higher compensation packages compared to smaller cities or regional areas.
What's the difference between a Site Reliability Engineer and a DevOps Engineer?
While Site Reliability Engineers (SRE) and DevOps Engineers often work closely together, many still confuse their distinct roles. This confusion usually stems from their collaborative environments and overlapping goals, particularly in improving software delivery and system reliability.
A Site Reliability Engineer primarily focuses on system reliability and scalability. Their key responsibilities include incident response, performance optimization, and ensuring high availability. They emphasize metrics such as Service Level Indicators (SLIs), Service Level Objectives (SLOs), and error budgets, and typically possess programming skills in low-level languages, alongside a deep understanding of system internals.
In contrast, a DevOps Engineer concentrates on continuous integration and deployment processes. Their role involves automation, managing CI/CD pipelines, and using infrastructure as code. They track deployment frequency and lead time as core metrics, often employing scripting and high-level programming languages, while possessing a broad knowledge of various tools and platforms.
| Site Reliability Engineer (SRE) | DevOps Engineer | |
|---|---|---|
| Primary Focus | System reliability and scalability | Continuous integration and deployment |
| Key Responsibilities | Incident response, availability, performance optimization | Automation, CI/CD pipelines, infrastructure as code |
| Metrics Emphasis | SLIs, SLOs, error budgets | Deployment frequency, lead time, MTTR |
| Programming Skills | Advanced, often low-level languages | Scripting, high-level languages |
| Infrastructure Knowledge | Deep understanding of system internals | Broad knowledge of tools and platforms |
| Team Interaction | Close collaboration with development teams | Bridge between development and operations |
| Problem-Solving Approach | Long-term reliability solutions | Streamlining development and operations processes |
| Typical Background | Software engineering, systems administration | IT operations, software development |
What are the ranks of Site Reliability Engineers?
Site Reliability Engineering (SRE) often confuses many due to its overlap with other IT roles, like DevOps. However, distinct ranks in the SRE domain help clarify responsibilities and expectations. Understanding these ranks will guide recruiters in identifying the right talent for their teams.
- Junior Site Reliability Engineer: This entry-level role is suitable for individuals new to SRE. They usually work under supervision, assisting with basic tasks such as monitoring system health and understanding incident management. Their focus is on learning the ropes and gaining experience.
- Site Reliability Engineer: At this level, engineers are expected to have a grasp of SRE principles and can independently handle tasks like automating operations and managing incidents. They play a significant role in maintaining the reliability of services.
- Senior Site Reliability Engineer: Senior SREs bring a wealth of experience and often lead projects. They are responsible for designing scalable systems and ensuring system robustness. They also mentor junior team members, guiding them through complex problems.
- Lead Site Reliability Engineer: Leads oversee the entire SRE team, setting the direction for projects and initiatives. They liaise with other departments to align SRE efforts with organizational goals. Strong leadership and communication skills are paramount at this rank.
- Site Reliability Engineering Manager: Managers focus on strategic planning and resource allocation for the SRE team. They ensure that best practices are followed while continuously improving the reliability of systems. The role requires a blend of technical expertise and managerial acumen.
For those looking to understand the nuances of the SRE role, a detailed site reliability engineer job description can be highly beneficial.
Hire the Best Site Reliability Engineers with Confidence
Throughout this guide, we've explored the various aspects of hiring a Site Reliability Engineer (SRE), from understanding their role and responsibilities to outlining the hiring process and necessary skills. We've also discussed important factors like structuring interviews and the cost implications of hiring SREs.
The key takeaway is that having a clear job description and using the right skills tests can make a significant difference in hiring accurately. Comprehensive assessments, like the site reliability test, are useful tools to gauge a candidate's capabilities effectively. By focusing on these elements, you can confidently find and hire the Site Reliability Engineers who meet your organization's needs.
Site Reliability Test
40 mins | 16 MCQs
The Site Reliability Engineer (SRE) Test uses scenario-based questions to evaluate knowledge of cloud technologies, system design, automation, and troubleshooting skills. It assesses understanding of infrastructure as code, continuous integration and deployment, and monitoring systems. The test also measures proficiency in scripting languages and hands-on coding for infrastructure problem-solving. It further includes real-world situations to examine critical thinking and incident management abilities.
Try Site Reliability Test
FAQs
What is the role of a Site Reliability Engineer?
Site Reliability Engineers ensure that a company's services are reliable, scalable, and efficient. They work to create a bridge between development and operations by applying software engineering practices to IT operations and infrastructure problems.
What skills should I look for in a Site Reliability Engineer?
Look for skills such as programming, system administration, networking, and cloud technologies. Familiarity with monitoring tools, automation, and incident management processes is also important.
What is the difference between a Site Reliability Engineer and a DevOps Engineer?
While both roles aim to improve development and operations collaboration, SREs focus more on reliability and performance through automation and software engineering, whereas DevOps engineers emphasize the development cycle and CI/CD pipelines.
Where can I find top Site Reliability Engineer candidates?
You can find SRE candidates on platforms like LinkedIn, GitHub, and specialized tech job boards. Networking at industry conferences and engaging with online communities can also be effective.
How can I assess the skills of a Site Reliability Engineer?
Use skills tests to evaluate their technical expertise. Consider utilizing our Site Reliability Test for a comprehensive skills assessment.
What are some red flags to watch for when hiring a Site Reliability Engineer?
Red flags include a lack of practical experience with scaling systems, poor problem-solving skills, and an inability to work effectively in cross-functional teams.
How do I structure an interview for a Site Reliability Engineer?
Structure the interview to include technical assessments, behavioral questions, and problem-solving scenarios. Ensure that you're evaluating not just technical skills but also cultural and team fit.
40 min skill tests.
No trick questions.
Accurate shortlisting.
We make it easy for you to find the best candidates in your pipeline with a 40 min skills test.
Try for freeRelated posts
Free resources

Join 1200+ companies in 80+ countries.
Try the most candidate friendly skills assessment tool today.

40 min tests.
No trick questions.
Accurate shortlisting.
No trick questions.
Accurate shortlisting.